O Imposto da Localização (Por Que a Tradução Manual Está Acabando com Suas Margens)
Você conhece bem essa rotina. O cliente precisa de versões em espanhol, francês e português brasileiro de um vídeo corporativo de 20 minutos. Você exporta um corte preliminar, faz upload em alguma ferramenta de transcrição no navegador, espera pela transcrição, copia tudo para um serviço de tradução, limpa a bagunça que ele fez com cada termo técnico e nome próprio, formata em SRT, importa de volta para o Premiere e depois repete esse ciclo inteiro mais duas vezes para os outros dois idiomas.
Isso não é um fluxo de trabalho. É um imposto. E é um imposto que você paga em horas, não em dinheiro — o que é pior, porque horas não aparecem em uma fatura.
Vamos ser específicos sobre o custo. Um editor competente fazendo localização manual para três idiomas em um vídeo de 20 minutos pode facilmente queimar de quatro a seis horas por ciclo de idioma. São doze a dezoito horas de trabalho que não são correção de cor, nem design de som, nem nada que realmente torne a edição melhor. É sobrecarga administrativa disfarçada de pós-produção.
As ferramentas baseadas em navegador tornaram isso um pouco menos doloroso por um tempo. Mas "um pouco menos doloroso" não é a mesma coisa que "resolvido". O problema fundamental de todo fluxo de idas e vindas é a perda de contexto. No momento em que você sai da timeline, você perde a relação entre o áudio, o visual e o significado. Uma ferramenta de transcrição não sabe que "a sequência" significa algo muito específico na sua série de tutoriais. Ela não sabe que o nome do seu apresentador é escrito de uma forma específica, ou que o nome do produto do seu cliente é um nome próprio que nunca deve ser traduzido. Ela apenas gera texto, e você passa o resto da tarde corrigindo.
Existe uma linha direta entre essa ineficiência e suas margens. As agências que não conseguem resolver o problema da localização ou cobram dos clientes um valor extra que as torna não competitivas, ou absorvem o custo e veem sua taxa horária despencar. Nenhum dos dois é um bom resultado. Os editores que estão escalando seu trabalho de localização agora são aqueles que descobriram como manter todo o processo dentro do NLE.
Por Que a Precisão de 99,5% do Whisper É Apenas Metade da Batalha (O Papel do Contexto do GPT-5.3)
O modelo Whisper da OpenAI é genuinamente impressionante na transcrição. Uma precisão de 99,5% na taxa de erro de palavras em áudio limpo não é texto de marketing — é um benchmark real, e ele se sustenta na prática na maioria das condições profissionais de gravação. Se o seu apresentador está bem microfonado e sua sala é tratada acusticamente, o Whisper vai te dar uma transcrição limpa mais rápido do que qualquer digitador humano.
Mas eis a questão: precisão de transcrição e qualidade de tradução são dois problemas completamente diferentes. O Whisper resolve um problema de fala para texto. No momento em que você pede que ele também faça a tradução, você está pedindo a um modelo treinado principalmente em reconhecimento de padrões acústicos para tomar decisões semânticas e culturais. Não é para isso que ele foi construído.
É aqui que o GPT-5.3 entra em cena, e por isso a arquitetura híbrida é importante. O GPT-5.3 opera no nível do modelo de linguagem. Ele entende contexto, registro, expressão idiomática e a relação entre as frases. Quando você o alimenta com uma transcrição do Whisper e pede para traduzir, ele não faz uma substituição palavra por palavra. Ele lê a passagem completa, entende a intenção e reconstrói essa intenção no idioma de destino.
A diferença prática aparece imediatamente em três áreas. Primeiro, nomes próprios: uma tradução pura do Whisper vai estropiar nomes de marcas, nomes de produtos e nomes de pessoas porque não tem como saber que eles não devem ser traduzidos. O GPT-5.3, quando devidamente instruído, os preserva. Segundo, jargão técnico: linguagem específica do setor que não tem equivalente direto em outro idioma é tratada com raciocínio real em vez de uma busca no dicionário. Terceiro, tom e registro: um tutorial que usa linguagem casual e direta em inglês não se torna automaticamente formal e rígido em francês — o GPT-5.3 pode manter o registro se você pedir.
A combinação do Whisper para precisão de transcrição e do GPT-5.3 para tradução contextual não é uma redundância. Eles resolvem metades diferentes do mesmo problema, e você precisa das duas metades resolvidas para produzir legendas que não envergonhem você ou seu cliente.
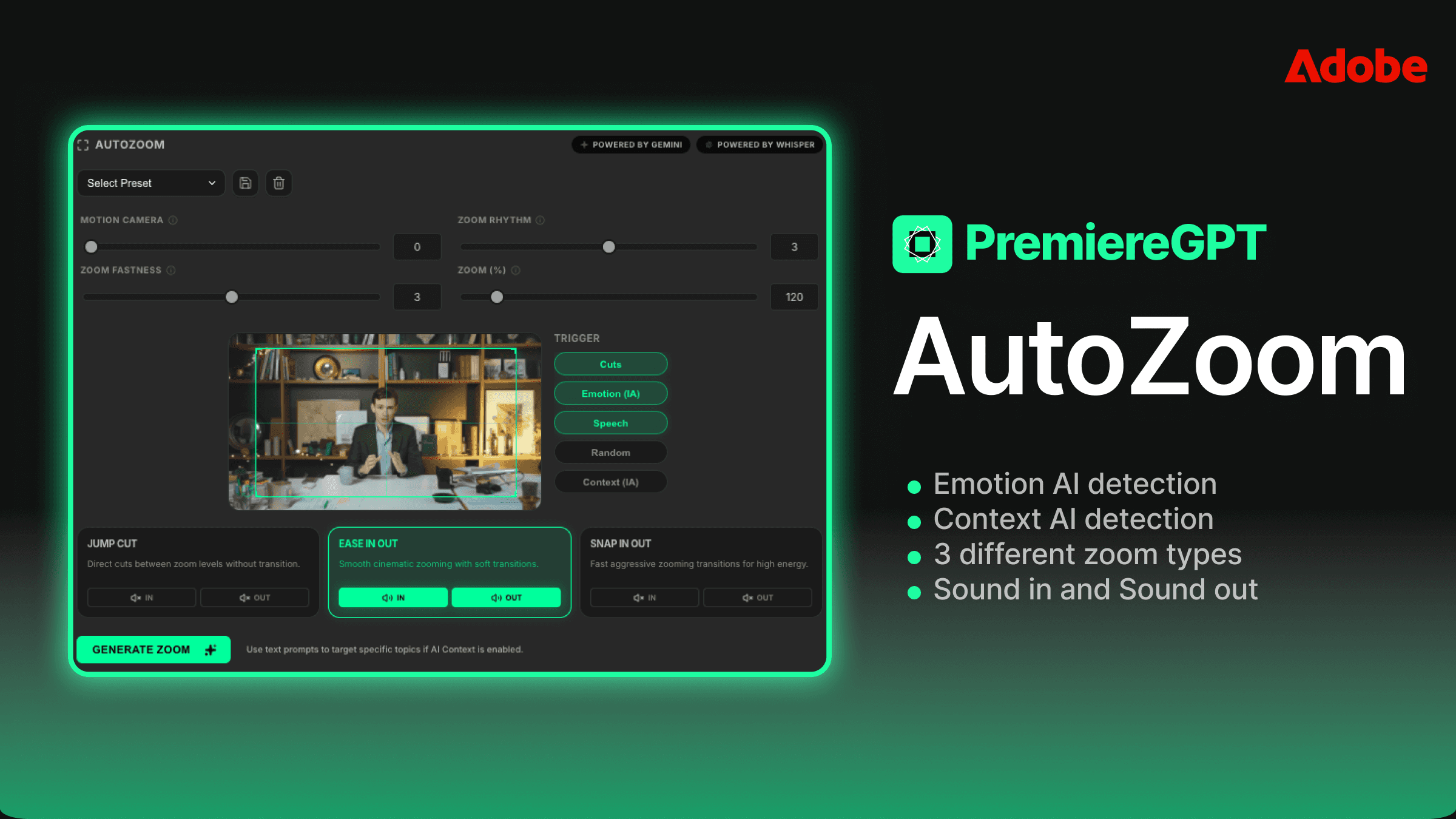
Indo Além do Inglês: Como Gerar Legendas para 99 Idiomas Simultaneamente
O fluxo de trabalho padrão do painel de Texto do Premiere Pro chega ao limite de qualquer que seja o seu nível de paciência para trabalho manual. Você pode gerar legendas em um idioma, pode fazer transcrição básica, mas no momento em que precisa escalar para vários idiomas, você volta ao ciclo de idas e vindas. O painel não foi projetado pensando em localização em escala.
Uma arquitetura de plugin Whisper/GPT-5.3 muda fundamentalmente essa conta. Em vez de processar um idioma por vez, você define seus idiomas de destino antecipadamente, e o pipeline processa todos eles contra a mesma transcrição mestre em uma única passagem. A transcrição do Whisper acontece uma vez. A camada de tradução do GPT-5.3 então se espalha para cada idioma de destino em paralelo, usando o mesmo contexto de origem para cada um.
Isso importa tecnicamente porque elimina a deriva de tradução. Quando você traduz sequencialmente — do inglês para o espanhol, depois do inglês para o francês, depois do inglês para o alemão — cada tradução é independente, e pequenos erros ou escolhas estilísticas não se acumulam. Mas, mais importante, o contexto de origem é idêntico para cada idioma, então você não está introduzindo variância na camada de transcrição que depois se propaga por cada tradução subsequente.
Em termos práticos: você define seus 99 idiomas de destino uma vez. Você roda o processo. Você recebe 99 arquivos SRT, todos sincronizados com a mesma sequência mestre, todos derivados da mesma transcrição do Whisper. O resultado vai direto para os bins do seu projeto, rotulados por código de idioma, prontos para serem aplicados à sequência correspondente.
O fluxo de trabalho não se importa se você precisa de dois idiomas ou de noventa e dois. O tempo de processamento escala, mas seu esforço manual não.
Configurando a Correção por Prompt (Ensinando à IA o Jargão do Seu Nicho)
Este é o recurso que separa uma ferramenta profissional de localização de um aplicativo de transcrição de consumo, e vale a pena gastar um tempo real na configuração. A correção por prompt permite que você injete um conjunto de instruções personalizadas na camada de processamento do GPT-5.3 antes que ela toque na sua transcrição. Você está essencialmente escrevendo um guia de estilo que o modelo lê antes de começar a traduzir.
Um prompt de correção bem construído para um canal de tutoriais de edição de vídeo pode parecer com algo assim: preserve todos os nomes próprios, incluindo nomes de softwares, nomes de plugins e atalhos de teclado em sua forma original; mantenha um tom direto e instrucional equivalente ao da fonte; não traduza os seguintes nomes de marcas: [lista]; quando o locutor usar o termo "sequência", traduza-o sempre como o equivalente direto no vocabulário profissional de edição de vídeo do idioma de destino, não a palavra genérica para "sequência".
Esse nível de especificidade é o que impede a camada do GPT-5.3 de tomar decisões bem-intencionadas, mas erradas. O modelo é capaz de raciocinar, mas precisa do seu conhecimento de domínio para raciocinar corretamente. Você sabe que "bin" significa uma pasta de projeto no Premiere. Você sabe que seu apresentador sempre se refere à técnica de "pancake timeline" por esse nome específico. O modelo não sabe nada disso até você dizer.
Construa seu prompt de correção uma vez por tipo de projeto e salve-o como um modelo. Um prompt para vídeo explicativo corporativo é diferente de um prompt para tutorial do YouTube, que é diferente de um prompt para documentário. Os quinze minutos que você gasta escrevendo um prompt sólido na primeira vez vão te poupar passagens de correção em cada projeto subsequente naquela categoria.
Uma técnica adicional que vale a pena implementar: inclua um bloco de glossário no final do seu prompt. Uma simples lista de duas colunas com os termos de origem e suas traduções aprovadas em cada idioma de destino dá ao modelo uma referência explícita para conferir. Para clientes com requisitos rígidos de linguagem de marca, isso é inegociável.
Traduções Infinitas vs. Cobrança por Minuto (A Matemática da Licença Vitalícia de US$ 59)
Vamos fazer as contas, porque é aqui que o argumento de negócio se torna inegável.
As principais ferramentas de transcrição e tradução baseadas em navegador cobram por minuto de áudio processado. As tarifas variam, mas um valor representativo fica em algum lugar entre US$ 0,10 e US$ 0,25 por minuto de áudio, por idioma. Para um vídeo de 20 minutos traduzido em cinco idiomas, você está olhando para US$ 10 a US$ 25 por projeto no mínimo. Isso parece administrável até você estar fazendo quinze projetos por mês e, de repente, estar gastando de US$ 150 a US$ 375 por mês em uma ferramenta que ainda exige uma ida e volta no navegador e ainda não conhece o seu jargão.
Ao longo de doze meses, isso dá de US$ 1.800 a US$ 4.500 em custos de assinatura. Para uma ferramenta que cria atrito no fluxo de trabalho.
Uma licença vitalícia de US$ 59 com traduções ilimitadas não tem um medidor por minuto rodando. O vigésimo idioma de um projeto custa o mesmo que o primeiro. O quinquagésimo projeto deste ano custa o mesmo que o primeiro. A matemática se inverte completamente: quanto maior o seu volume, melhor fica a proposta de valor. Com quinze projetos por mês com cinco idiomas cada, você recuperou um investimento de US$ 59 já no primeiro projeto do primeiro mês.
O ponto mais importante é estrutural. A cobrança por minuto cria um incentivo perverso para fazer menos localização do que você deveria. Quando cada idioma custa dinheiro, você começa a tomar decisões sobre quais mercados vale a pena atender com base nos custos da ferramenta, e não nas necessidades do cliente ou no tamanho do público. Um modelo de preço fixo remove esse atrito por completo. Você traduz para todos os idiomas que fazem sentido para o conteúdo, sem fazer um cálculo mental de custo-benefício a cada vez.
Para agências que oferecem pacotes de localização aos clientes, isso também muda o seu modelo de precificação. Quando o seu custo marginal por idioma adicional se aproxima de zero, você pode agrupar idiomas em pacotes de preço fixo sem se preocupar que seus custos escalem linearmente com o tamanho do pacote. Isso é uma vantagem competitiva em uma proposta.
Fluxo de Trabalho: Da Sequência Mestre às Exportações Localizadas em 3 Cliques
Veja como é o fluxo de trabalho real dentro do Premiere quando está configurado corretamente. Sem abas de navegador. Sem exportações de arquivos. Sem ginástica com a área de transferência.
Você finaliza sua sequência mestre. Imagem travada, áudio mixado, gráficos finalizados. Abra o painel do plugin — ele fica no mesmo espaço de trabalho que o seu painel de Texto, encaixado onde você preferir. Sua sequência mestre já está selecionada como fonte. Passo um: selecione seus idiomas de destino na lista de idiomas. Você pode salvar conjuntos de idiomas como predefinições, então se você sempre entrega espanhol, francês e alemão, é uma seleção de um clique.
Passo dois: aplique seu prompt de correção. Se você salvou modelos por tipo de projeto, você seleciona em um menu suspenso. Se este é um novo tipo de projeto, você cola o seu prompt preparado. De qualquer forma, isso leva menos de trinta segundos.
Passo três: rode o processo. O Whisper ingere o áudio da sua sequência diretamente — nenhuma exportação é necessária, porque o plugin lê o áudio da timeline do Premiere via API. O GPT-5.3 processa a transcrição contra cada idioma de destino usando o seu prompt. O resultado é um conjunto de arquivos SRT e, opcionalmente, faixas de legenda que são automaticamente importadas de volta para os bins do seu projeto, rotuladas por código de idioma ISO.
A partir daí, aplicar uma faixa de legenda a uma sequência localizada é uma operação de arrastar e soltar. Se você está entregando exportações separadas por idioma, você duplica sua sequência mestre, aplica a faixa de legenda correspondente e exporta. Se você está entregando um único arquivo com fluxos de legenda incorporados, os SRTs já estão formatados para esse fluxo de trabalho.
A descrição de três cliques não é um exagero para um fluxo de trabalho configurado. O tempo de configuração é adiantado na criação do modelo de prompt e da predefinição de idiomas, que você faz uma vez. Depois disso, a execução por projeto é genuinamente assim de rápida.
Boas Práticas para Exportação de SRT e Importação Automática
Uma saída SRT limpa exige atenção a alguns parâmetros técnicos que são fáceis de ignorar e dolorosos de corrigir mais adiante.
Os limites de caracteres por linha variam conforme a plataforma de entrega e o contexto de visualização. Os padrões de legendagem para transmissão geralmente limitam a 37 caracteres por linha, com um máximo de duas linhas. As plataformas online são mais permissivas — YouTube e Vimeo lidam com 42 caracteres por linha sem problemas de exibição na maioria dos tamanhos de tela — mas ir além disso cria problemas de legibilidade no celular. Defina seu limite de caracteres nas configurações de exportação antes de processar, não depois. Reformatar o tempo das legendas posteriormente para acomodar linhas mais curtas é um esforço manual significativo.
A velocidade de leitura é o outro parâmetro de tempo que separa legendas profissionais das amadoras. O padrão para espectadores adultos é 17 caracteres por segundo. Para conteúdo voltado a públicos mais jovens ou contextos educacionais, 13 caracteres por segundo é mais seguro. As traduções do GPT-5.3 podem ficar mais longas que a fonte em alguns pares de idiomas — alemão e finlandês são notórios por palavras compostas que se expandem significativamente — então incorporar uma verificação de velocidade de leitura como parte da sua validação de exportação detecta violações de tempo antes que elas se tornem uma revisão do cliente.
Para a importação automática de volta no Premiere, nomeie seus arquivos SRT com o código de idioma ISO 639-1 como sufixo antes que eles cheguem aos seus bins. nomedoprojeto_es.srt, nomedoprojeto_fr.srt, nomedoprojeto_de.srt. Essa convenção de nomenclatura torna as operações em lote e a rotulagem de sequências significativamente mais limpas, especialmente quando você está gerenciando um projeto com dez ou mais entregas de idiomas.
A segurança de fontes para legendas localizadas é uma questão separada que pega muitos editores de surpresa. Uma predefinição de legenda que usa uma fonte personalizada será exibida corretamente na sua máquina e quebrará em qualquer outra máquina que não tenha aquela fonte instalada. Para entregas SRT que os clientes usarão de forma independente, atenha-se a fontes seguras do sistema ou incorpore as informações de fonte explicitamente nas suas especificações de entrega. Para legendas queimadas (burn-in), isso é menos problemático, mas documente suas escolhas de fonte nas suas notas de entrega de qualquer forma.
O alinhamento da taxa de quadros entre sua sequência mestre e o tempo do seu SRT é inegociável. Um SRT gerado contra uma timeline de 29,97fps vai derivar em relação a uma sequência de 25fps. Confirme a taxa de quadros da sua sequência antes de rodar o processo de transcrição, e confirme novamente antes de exportar. É uma verificação de trinta segundos que evita uma faixa de legenda meio segundo fora de sincronia no final de um vídeo de vinte minutos.
Os editores que escalam seu trabalho de localização não estão fazendo mais trabalho manual. Eles estão fazendo o mesmo trabalho uma vez, com um sistema que multiplica o resultado. A ida e volta no navegador não é apenas lenta — é um gargalo estrutural que limita quanto volume de localização você consegue dar conta. Remova o gargalo, e o teto de volume desaparece.
Se você quiser levar este fluxo de trabalho mais longe, montamos um documento de referência prático para exatamente esse tipo de cenário de entrega. A Checklist de Exportação do Criador Global cobre compatibilidade de taxa de quadros, limites de caracteres por plataforma, segurança de fontes para conjuntos de caracteres internacionais e inclui cinco predefinições de legenda prontas para uso, criadas para entrega global. É a folha de referência que deveria estar aberta no seu segundo monitor toda vez que você estiver preparando uma exportação localizada. Pegue-a abaixo e pare de reconstruir essas informações do zero em cada projeto internacional.