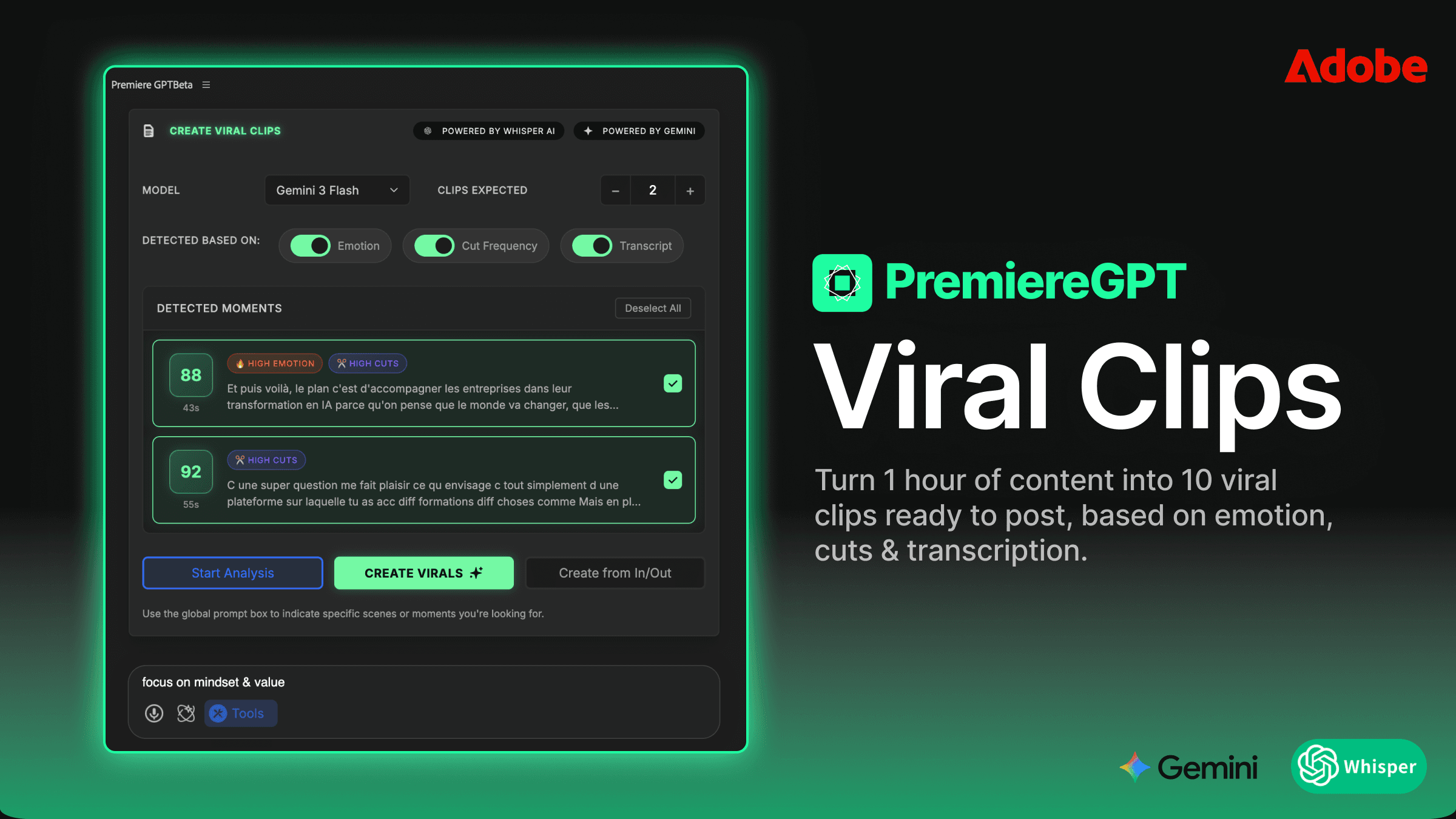
A armadilha da edição de retenção: por que os punch-ins manuais estão acabando com a sua hora de trabalho
Você conhece essa edição. Imagens de uma pessoa falando para a câmera. Câmera única. O cliente quer que tudo pareça "dinâmico" — energético, impactante, feito para públicos de atenção curta. Então você senta e começa a fazer aquilo. Você assiste a uma frase, coloca uma palavra-chave na propriedade Escala, aumenta 15%, suaviza a entrada, suaviza a saída, move o cursor de reprodução e repete. Em uma entrevista de 10 minutos, você está olhando para algo entre 40 e 80 momentos de zoom individuais. São centenas de palavras-chave. Feitas à mão.
Essa é a armadilha da edição de retenção. O estilo foi popularizado por uma onda de conteúdo social de alto volume — aquele em que algo muda visualmente a cada três segundos para que o dedo do espectador fique parado. Funciona. O problema é o custo da mão de obra. Se você cobra um valor fixo por vídeo e gasta quatro horas só com punch-ins, você está perdendo dinheiro ativamente toda vez que abre essa sequência.
E a pior parte? A maioria desses zooms é arbitrária. Você não está reagindo à entrega do orador. Você está apenas preenchendo o espaço com movimento porque a edição parece estática demais. Você está aplicando uma técnica sem um gatilho real, o que significa que o resultado muitas vez parece mecânico de qualquer forma — zooms que caem na sílaba errada, punch-ins que acontecem durante uma respiração em vez de uma frase de efeito.
Existe uma maneira melhor de fazer isso, e ela começa separando a questão de quando dar zoom da questão de como executá-lo. A primeira parte — o quando — é, na verdade, um problema de dados. E problemas de dados podem ser automatizados.
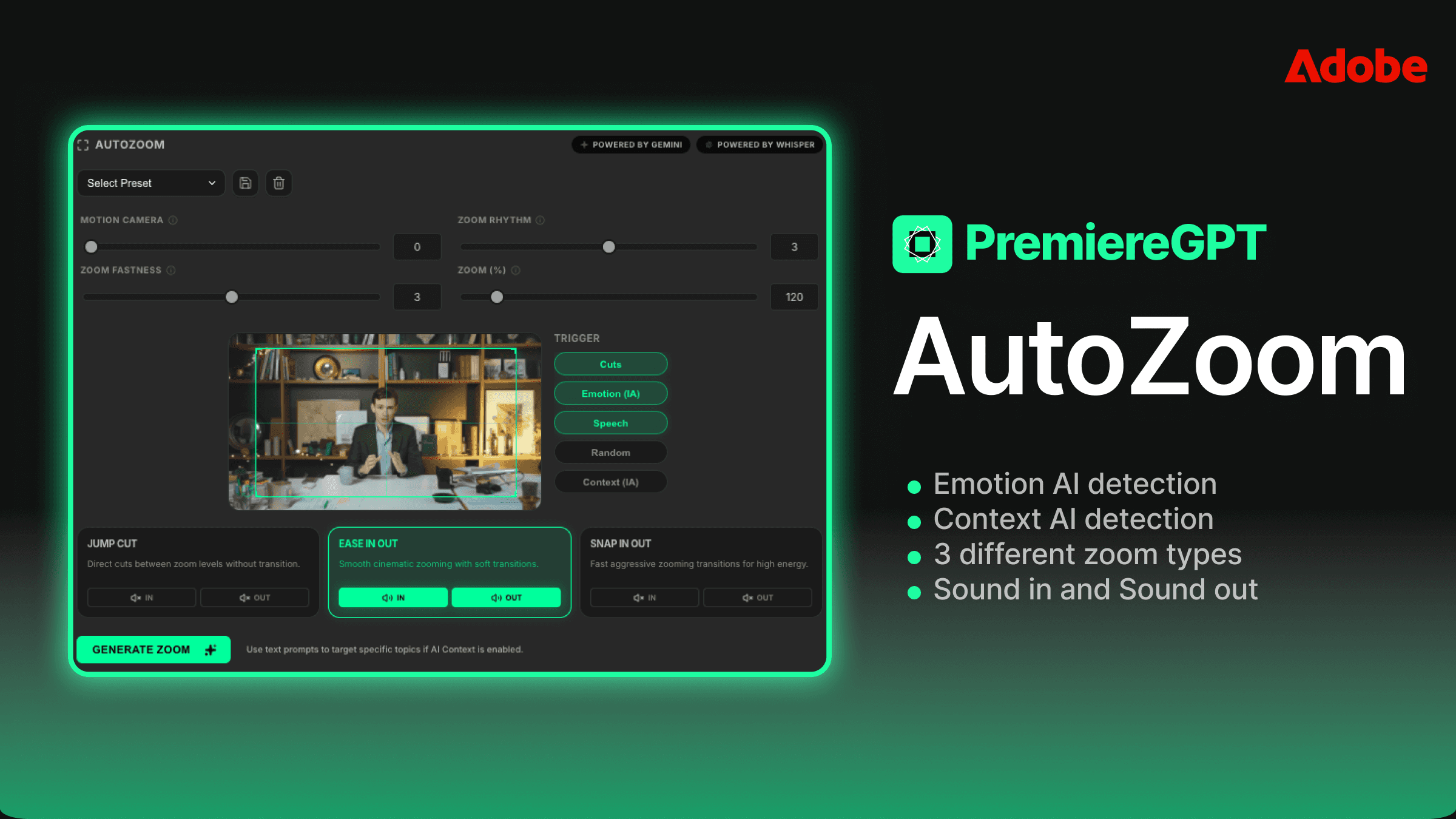
Detecção de emoção vs. matemática estática: como o algoritmo identifica os momentos de 'pico' para um zoom
A maioria dos plugins básicos de zoom automático funciona com matemática estática. Eles olham a amplitude do áudio, encontram os transientes mais altos e colocam um zoom nesses quadros. É um instrumento grosseiro. Alto não significa importante. Um orador limpando a garganta é alto. Uma batida na mesa é alta. O momento real de ênfase emocional — a pausa antes da palavra-chave, a leve elevação de tom em uma frase crítica — esses muitas vezes não são os momentos mais altos da forma de onda. São os momentos mais significativos, e só a amplitude não consegue encontrá-los.
A detecção de emoção funciona em uma camada diferente. Em vez de apenas ler o sinal de áudio, ela analisa o conteúdo da fala, a prosódia (o ritmo, a tonicidade e a entonação da fala) e o peso semântico do que está sendo dito. O algoritmo faz uma pergunta fundamentalmente diferente. Ele não pergunta "onde está o pico de áudio?". Ele pergunta "onde o orador está no auge da entrega emocional?".
Na prática, isso significa que o sistema consegue identificar momentos como um orador se aprofundando em uma conclusão, uma pergunta retórica que faz efeito, um momento de vulnerabilidade ou ênfase — o tipo de batida que um editor experiente sentiria instintivamente ao assistir às imagens. A IA não está assistindo às imagens, mas está interpretando os mesmos sinais aos quais um editor habilidoso responderia: mudança de tom, mudança de ritmo, clímax semântico.
O resultado é um posicionamento de zoom que realmente acompanha o arco da entrega do orador, em vez de apenas os picos mais altos do arquivo de áudio. Quando você revisa os efeitos gerados por IA na sua timeline, vai perceber que os punch-ins caem em momentos que você mesmo teria escolhido — o que significa menos tempo corrigindo posicionamentos ruins e mais tempo fazendo os poucos ajustes que realmente exigem julgamento editorial.
Isso não é mágica. É uma tarefa de automação bem delimitada. O algoritmo não está tomando decisões criativas — ele está revelando os momentos com maior probabilidade estatística de se beneficiar de uma ênfase visual. Você ainda decide se essa ênfase é adequada para a peça específica. Mas agora você toma essa decisão em 10% dos zooms, em vez de posicionar 100% deles do zero.
Além do recorte: personalizando velocidade, sound design e prompts de contexto de IA para a 'vibe' perfeita
Um zoom não é apenas um zoom. A diferença entre um punch-in de 4 quadros com um som de "whoosh" e um avanço suave de 12 quadros sem tratamento de áudio é a diferença entre um vídeo de hype e um documentário. Velocidade e sound design são as variáveis que definem o registro emocional de uma edição de retenção, e qualquer ferramenta de automação séria precisa dar a você controle sobre ambos.
Ao configurar suas passagens de zoom automático, você trabalha com dois perfis de velocidade principais. Zooms rápidos — normalmente de 3 a 6 quadros — são seus cortes de alta energia. Funcionam para conteúdo motivacional, momentos de reação, frases de efeito. Eles parecem agressivos e devem parecer. Zooms suaves — de 10 a 20 quadros com interpolação suavizada — são para conteúdo narrativo, batidas emocionais, segmentos explicativos em que você quer atrair o espectador em vez de assustá-lo. Usar o perfil de velocidade errado no momento certo ainda é uma edição ruim.
A sobreposição de sound design nos zooms costuma ser tratada como algo secundário, mas é, na verdade, um dos elementos de maior impacto na estrutura de uma edição de retenção. Um sutil baque de baixa frequência sob um avanço lento adiciona peso. Um swish agudo e curto sob um punch-in rápido adiciona impacto. O tratamento de áudio diz ao cérebro do espectador como se sentir em relação ao movimento visual antes mesmo de processá-lo conscientemente.
O recurso de prompt de contexto de IA é onde o fluxo de trabalho fica genuinamente sofisticado. Em vez de aplicar um algoritmo de zoom de tamanho único, você pode alimentar o sistema com uma breve descrição da intenção emocional do conteúdo. Um prompt como "conteúdo empresarial motivacional, alta energia, orador confiante" vai calibrar o limiar de detecção de forma diferente de "história pessoal, vulnerabilidade emocional, ritmo lento". O algoritmo usa o contexto para ponderar quais sinais emocionais priorizar ao selecionar os pontos de gatilho do zoom.
Pense nisso como instruir a IA da mesma forma que você instruiria um editor júnior. Você não está dando a ela um roteiro quadro a quadro — está dando contexto suficiente para que tome decisões melhores dentro do seu escopo de atuação. Quanto mais específico for o seu prompt, mais o resultado reflete o tom real da peça, em vez de um modelo genérico de edição de retenção.
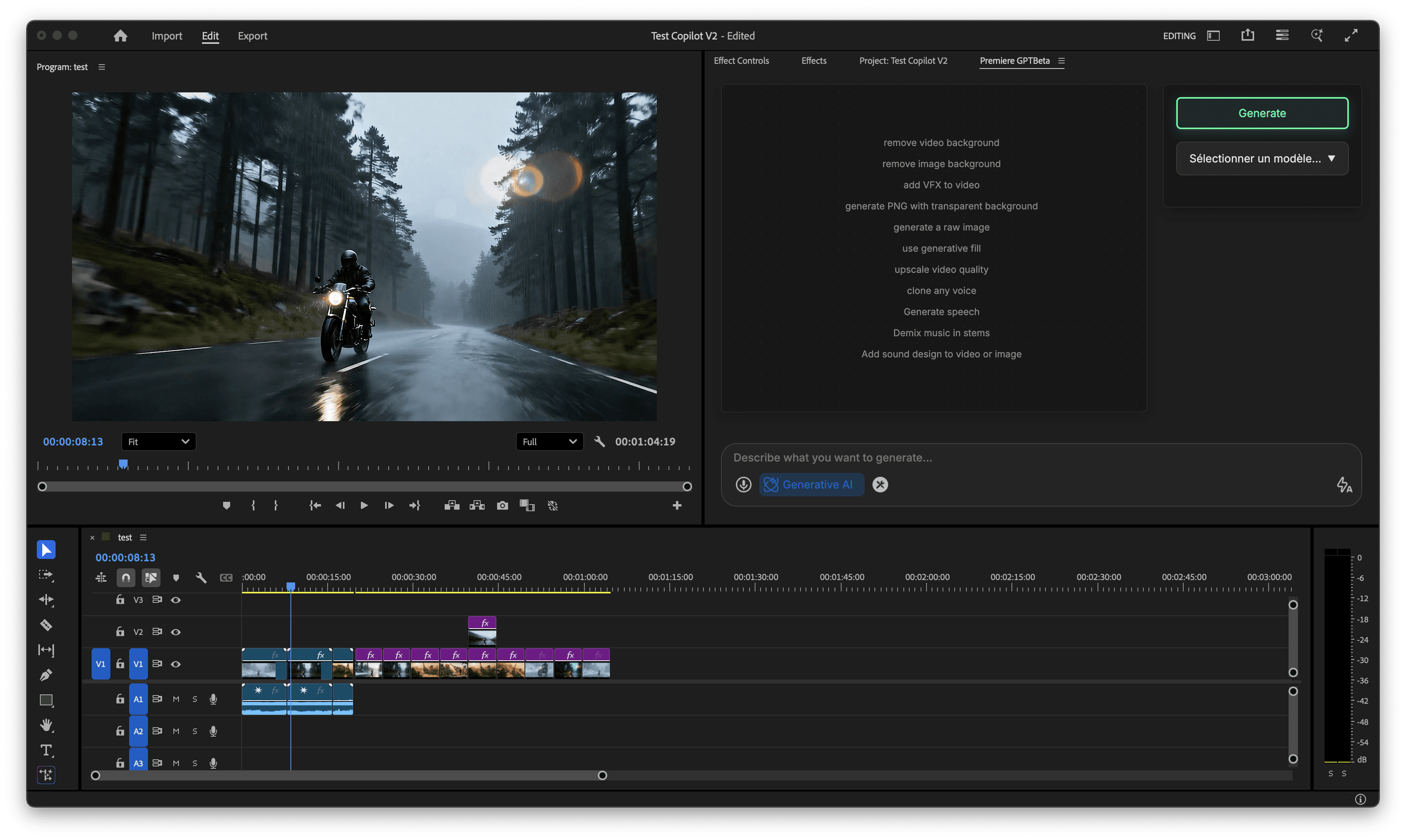
Fluxo de trabalho não destrutivo: por que manter os zooms em camadas de efeitos é sempre melhor do que sequências aninhadas
Esta é a parte que mais importa do ponto de vista de um fluxo de trabalho profissional, e é a parte que separa uma ferramenta que vale a pena usar de uma ferramenta que cria mais problemas do que resolve.
Quando o PremiereCopilot aplica zooms automáticos à sua timeline, ele não incorpora o movimento aos seus clipes. Ele não aninha suas imagens. Ele não toca na sua mídia original. Ele aplica os efeitos de zoom como Camadas de Efeitos — camadas dedicadas, do tipo de ajuste, posicionadas acima das suas imagens na timeline, contendo todas as palavras-chave de Escala e Posição geradas pela passagem da IA.
Por que isso importa? Porque sequências aninhadas são uma armadilha. Assim que você aninha um clipe para aplicar movimento a ele, você adicionou uma camada de abstração entre você e a sua edição. Precisa aparar o clipe? Agora você está gerenciando pontos de entrada e saída em dois níveis da timeline. Precisa trocar as imagens subjacentes? Você tem que entrar no aninhamento. Precisa remover o zoom por completo? Você ou deleta o aninhamento ou entra dentro dele. Toda operação que deveria ser simples se torna um processo de duas etapas.
As Camadas de Efeitos mantêm tudo na mesma profundidade da timeline. O zoom está em uma camada acima do clipe. Você pode vê-lo, selecioná-lo, deletá-lo, movê-lo ou ajustar suas palavras-chave diretamente no painel Controles de Efeito — exatamente da mesma forma que você trabalharia com qualquer outro efeito no Premiere Pro. A IA fez o trabalho pesado de posicionamento e timing, mas você tem 100% de controle editorial sobre cada zoom gerado. Nada fica travado. Nada fica escondido dentro de um aninhamento.
Essa arquitetura também significa que os zooms são totalmente portáteis. Se você precisa mover um clipe na timeline, a Camada de Efeitos se move junto com ele. Se você quer copiar um tratamento de zoom de um segmento para outro, está copiando uma camada, não duplicando uma sequência aninhada com toda a sobrecarga que isso implica.
Para editores que produzem conteúdo social em alto volume — várias edições por semana, várias proporções de tela, ciclos rápidos de revisão — essa abordagem não destrutiva não é um luxo. É o único fluxo de trabalho que escala sem criar dívida técnica nos seus arquivos de projeto.
Como configurar suas predefinições de AutoZoom para edições sociais 10x mais rápidas
O verdadeiro ganho de eficiência do zoom assistido por IA não vem de uma única execução em um único vídeo. Ele vem da construção de uma biblioteca de predefinições que reflita seu estilo de edição específico e os tipos de conteúdo específicos dos seus clientes. Veja como estruturar esse sistema.
Passo um: defina suas categorias de conteúdo. A maioria dos editores que trabalham com conteúdo social está editando uma série de tipos de conteúdo recorrentes — conteúdo motivacional/empresarial, explicações educativas, narrativas pessoais, cortes de entrevista/podcast. Cada um deles tem uma densidade de zoom ideal diferente (quantos zooms por minuto), um perfil de velocidade diferente e um tratamento de sound design diferente. Documente isso antes de construir suas predefinições.
Passo dois: construa suas predefinições básicas por categoria. Para cada tipo de conteúdo, configure uma predefinição com sua densidade de zoom, seu perfil de velocidade (rápido vs. suave), sua camada de sound design preferida e seu prompt de contexto de IA padrão. Nomeie essas predefinições com clareza — "Empresarial Motivacional - Alta Energia", "Corte de Podcast - Conversacional", "História - Emocional". Quando um novo projeto chega, você seleciona uma predefinição, não reconstrói suas configurações do zero.
Passo três: execute a passagem da IA e faça uma única passagem de revisão. Depois que o zoom automático roda e as Camadas de Efeitos são colocadas na sua timeline, faça uma passagem de revisão focada. Você não está construindo nada — está apenas removendo zooms que não funcionam e, ocasionalmente, ajustando o timing daqueles que estão próximos, mas não exatos. Em uma predefinição bem configurada aplicada a um conteúdo apropriado, você deveria remover ou ajustar menos de 20% dos zooms gerados. Se você está ajustando mais do que isso, sua predefinição precisa de refinamento, não de mais trabalho manual.
Passo quatro: itere seus prompts com base nos resultados. Mantenha uma anotação contínua de quais prompts de contexto de IA produziram o melhor posicionamento de zoom para cada tipo de conteúdo. Com o tempo, você vai desenvolver um vocabulário de prompts ajustado aos seus clientes e estilos de conteúdo específicos. Esse é o retorno cumulativo do sistema — cada vídeo que você edita torna suas predefinições um pouco mais precisas, o que significa um pouco menos de trabalho de revisão no próximo.
Passo cinco: construa suas variantes de cortes sociais a partir da mesma pilha de Camadas de Efeitos. Se você está editando uma peça longa em 16:9 e um curto em 9:16 a partir das mesmas imagens, suas Camadas de Efeitos podem ser adaptadas em vez de reconstruídas. As posições e o timing do zoom já estão estabelecidos — você está ajustando os valores de Escala e os pontos de ancoragem para o reenquadramento, não reexecutando toda a passagem da IA do zero.
A economia de tempo acumulada ao longo de um mês de trabalho com conteúdo social é significativa. Estamos falando de passar de quatro horas de trabalho manual de zoom por vídeo para menos de 45 minutos de configuração, revisão e refinamento. Isso não é uma estimativa tirada de uma apresentação de marketing — é a matemática de substituir centenas de palavras-chave manuais por uma única passagem de IA e uma revisão editorial focada.
O objetivo nunca foi remover o editor do processo. O objetivo é remover as partes mecânicas do processo para que o tempo do editor seja gasto em decisões que realmente exigem julgamento.
Se você ainda está colocando manualmente palavras-chave nas propriedades de Escala em cada corte de uma pessoa falando, você não está editando — está digitando dados. A técnica tem o seu lugar, mas a execução deveria ser automatizada sempre que a automação for precisa o suficiente para se confiar nela. Com a detecção de emoção conduzindo o posicionamento e as Camadas de Efeitos preservando o seu controle, ela é.
Pronto para parar de criar predefinições de zoom do zero toda vez? Baixe o Guia Prático de Edição de Retenção — um guia em PDF que aborda exatamente quando usar os perfis de zoom Rápido vs. Suave, uma lista selecionada de prompts de contexto de IA organizados por tipo de conteúdo e uma tabela de referência de densidade de zoom para os formatos sociais mais comuns. Tudo o que você precisa para configurar sua primeira passagem de zoom assistida por IA e obter resultados que você vai realmente manter na edição.