ローカライズという「見えない税金」(手作業の翻訳があなたの利益を削っている理由)
お決まりのパターンですよね。クライアントが20分の企業向け動画のスペイン語版、フランス語版、ブラジルポルトガル語版を必要としている。あなたはラフカットを書き出し、ブラウザベースの文字起こしツールにアップロードし、トランスクリプトを待ち、それを翻訳サービスにコピーし、専門用語や固有名詞がめちゃくちゃにされた箇所を修正し、SRTに整形してPremiereに読み込み直し、残り2言語ぶん同じループをもう2回繰り返す。
これはワークフローではありません。「税金」です。しかもドルではなく時間で支払う税金なので、なお質が悪い。時間は請求書には載らないからです。
コストを具体的に見てみましょう。有能なエディターが20分の動画を3言語に手作業でローカライズすると、1言語サイクルあたり4〜6時間は簡単に消えます。つまり12〜18時間。それはカラーグレーディングでもサウンドデザインでもなく、編集を実際に良くする作業ではまったくありません。ポストプロダクションを装った、ただの事務的なオーバーヘッドです。
ブラウザベースのツールは一時的にこの苦痛を少しだけ和らげました。しかし「少しマシ」は「解決」とは違います。あらゆる往復ワークフローの根本的な問題は、コンテキストの喪失です。タイムラインを離れた瞬間に、音声・映像・意味の関係性が失われます。文字起こしツールは、あなたのチュートリアルシリーズで「シーケンス」が特定の意味を持つことを知りません。ホストの名前のスペルや、クライアントの製品名が決して翻訳してはいけない固有名詞であることも知りません。ただテキストを生成するだけで、あなたは午後の残りをその修正に費やすことになります。
この非効率はあなたの利益率に直結します。ローカライズの問題を解決できないエージェンシーは、競争力を失うほどの割増料金をクライアントに請求するか、コストを自己負担して時間単価が崩壊するのを眺めるかのどちらかです。どちらも良い結末ではありません。今この瞬間にローカライズ業務をスケールさせているエディターは、プロセス全体をNLE(編集ソフト)の中に留める方法を見つけた人たちです。
Whisperの99.5%の精度は戦いの半分にすぎない理由(GPT-5.3のコンテキストの役割)
OpenAIのWhisperモデルは、文字起こしにおいて本当に優秀です。クリーンな音声で単語誤り率99.5%の精度というのは宣伝文句ではなく、実際のベンチマークであり、ほとんどのプロの収録環境で通用します。エディターがしっかりマイク収録され、部屋が音響処理されていれば、Whisperはどんな人間のタイピストよりも速くクリーンなトランスクリプトを返します。
しかし重要な点があります。文字起こしの精度と翻訳の品質は、まったく別の問題です。Whisperが解いているのは音声→テキストの問題です。そこに翻訳まで任せようとした瞬間、主に音響パターン認識で訓練されたモデルに、意味的・文化的な判断をさせることになります。それはWhisperが作られた目的ではありません。
ここでGPT-5.3が登場します。そしてこのハイブリッド構成が重要な理由でもあります。GPT-5.3は言語モデルのレベルで動作します。コンテキスト、文体、慣用表現、文と文の関係性を理解します。Whisperのトランスクリプトを与えて翻訳を頼んでも、単語の機械的な置き換えはしません。文章全体を読み、意図を理解し、その意図をターゲット言語で再構築するのです。
実務上の違いは3つの領域ですぐに現れます。第一に固有名詞。純粋なWhisper翻訳は、ブランド名・製品名・人名を台無しにします。翻訳してはいけないと判断する術がないからです。GPT-5.3は適切にプロンプトを与えれば、それらを保持します。第二に専門用語。他言語に直接の対応語がない業界特有の言葉を、辞書引きではなく実際の推論で扱います。第三にトーンと文体。英語でカジュアルで率直な言葉づかいのチュートリアルが、フランス語で自動的に堅苦しくなることはありません。指示すればGPT-5.3は文体を維持できます。
文字起こし精度のためのWhisperと、文脈翻訳のためのGPT-5.3の組み合わせは、冗長ではありません。同じ問題の異なる半分をそれぞれ解いており、あなたやクライアントを恥ずかしい思いにさせない字幕を作るには、両方の半分を解く必要があります。
英語の先へ:99言語の字幕を同時に生成する方法
標準的なPremiere Proのテキストパネルのワークフローは、あなたの手作業への忍耐の限界で頭打ちになります。1言語のキャプションは生成できますし、基本的な文字起こしもできます。しかし複数言語へスケールする必要が出た瞬間、また往復ループに逆戻りです。あのパネルは、大規模なローカライズを想定して設計されていません。
Whisper/GPT-5.3のプラグイン構成は、この根本的な計算を変えます。1言語ずつ処理する代わりに、ターゲット言語を最初に定義し、パイプラインがそれらすべてを同一のマスタートランスクリプトに対して1回のパスで処理します。Whisperの文字起こしは1回だけ。そのうえでGPT-5.3の翻訳レイヤーが、同じソースコンテキストを使って全ターゲット言語へ並列に展開します。
これが技術的に重要なのは、翻訳のドリフトを排除できるからです。英語→スペイン語、次に英語→フランス語、次に英語→ドイツ語と逐次的に翻訳すると、各翻訳が独立してしまい、わずかな誤りや文体の選択が積み重なります。さらに重要なのは、すべての言語でソースコンテキストが同一になるため、文字起こしレイヤーでばらつきを持ち込んで下流の全翻訳に伝播させることがなくなる点です。
実務的には、99のターゲット言語を一度設定する。プロセスを実行する。同じマスターシーケンスにタイミングが合った99のSRTファイルが、すべて同じWhisperトランスクリプトから生成されて手に入ります。出力は言語コードでラベル付けされ、直接プロジェクトのビンに格納され、対応するシーケンスに適用できる状態になります。
ワークフローは、必要な言語が2つでも92でも気にしません。処理時間はスケールしますが、あなたの手作業はスケールしないのです。
プロンプトベースの修正をセットアップする(AIにあなたの専門用語を教える)
これがプロ向けのローカライズツールと消費者向けの文字起こしアプリを分ける機能であり、しっかり時間をかけてセットアップする価値があります。プロンプトベースの修正を使うと、GPT-5.3の処理レイヤーがトランスクリプトに触れる前に、カスタムの指示セットを注入できます。要するに、モデルが翻訳を始める前に読むスタイルガイドを書くわけです。
動画編集チュートリアルチャンネル向けのよく練られた修正プロンプトは、たとえばこんな感じになります。ソフトウェア名・プラグイン名・キーボードショートカットを含むすべての固有名詞は原語のまま保持する。ソースと同等の直接的で説明的なトーンを維持する。次のブランド名は翻訳しない:[リスト]。話者が「シーケンス」という語を使ったときは、汎用的な「順序」の語ではなく、必ずターゲット言語のプロの動画編集用語の対応語に訳す。
このレベルの具体性こそが、GPT-5.3レイヤーが善意ながら誤った判断をするのを防ぎます。モデルは推論ができますが、正しく推論するにはあなたのドメイン知識が必要です。Premiereでは「ビン」がプロジェクトフォルダを意味すること、ホストがいつもあの「パンケーキタイムライン」テクニックをその名前で呼ぶこと——あなたは知っています。モデルは、あなたが教えるまでそれを知りません。
修正プロンプトはプロジェクトタイプごとに一度作り、テンプレートとして保存しましょう。企業向け説明動画のプロンプトはYouTubeチュートリアルのプロンプトとは違い、それはドキュメンタリーのプロンプトとも違います。最初にしっかりしたプロンプトを書くのに費やす15分が、そのカテゴリーの以降すべてのプロジェクトで修正パスを省いてくれます。
実装する価値のあるもう一つのテクニック:プロンプトの末尾に用語集ブロックを入れることです。ソース用語と各ターゲット言語での承認済み訳語をまとめた2列の簡単なリストがあれば、モデルが照合できる明示的なリファレンスになります。厳格なブランド用語要件のあるクライアントには、これは必須です。
無制限の翻訳 vs 分単位課金($59買い切りライセンスの計算)
数字を出してみましょう。ここでビジネス上の根拠が動かしがたいものになります。
主流のブラウザベースの文字起こし・翻訳ツールは、処理した音声の分数で課金します。レートはさまざまですが、代表的な数字は1言語あたり音声1分につき$0.10〜$0.25あたりです。20分の動画を5言語に翻訳すると、安く見積もっても1プロジェクトあたり$10〜$25。月に15プロジェクトこなすまでは管理可能に思えますが、そうなると月$150〜$375を、ブラウザの往復を要し、しかもあなたの専門用語を知らないツールに費やすことになります。
12か月では$1,800〜$4,500の購読費用です。ワークフローに摩擦を生むツールのために。
翻訳無制限の$59買い切りライセンスには、分単位のメーターが回っていません。プロジェクトの20番目の言語も1番目と同じコストです。今年の50番目のプロジェクトも最初と同じコストです。計算は完全に逆転します。ボリュームが大きいほど、コストパフォーマンスは良くなる。月15プロジェクトでそれぞれ5言語なら、$59の投資は初月の最初のプロジェクトあたりでほぼ回収できます。
より重要なのは構造的な点です。分単位課金は、本来やるべきよりも少ないローカライズしかしないという、ゆがんだインセンティブを生みます。どの言語にもお金がかかると、クライアントのニーズや視聴者規模ではなく、ツールのコストを基準に「どの市場に対応する価値があるか」を判断し始めてしまう。定額モデルはその摩擦を完全に取り除きます。毎回頭の中でコスト便益を計算することなく、コンテンツにとって理にかなうあらゆる言語に翻訳できます。
クライアントにローカライズパッケージを提案するエージェンシーにとって、これは料金モデルそのものも変えます。追加言語あたりの限界コストがゼロに近づくと、バンドルサイズに比例してコストが増えることを心配せずに、言語を定額パッケージにまとめられます。提案書における競争上の優位性です。
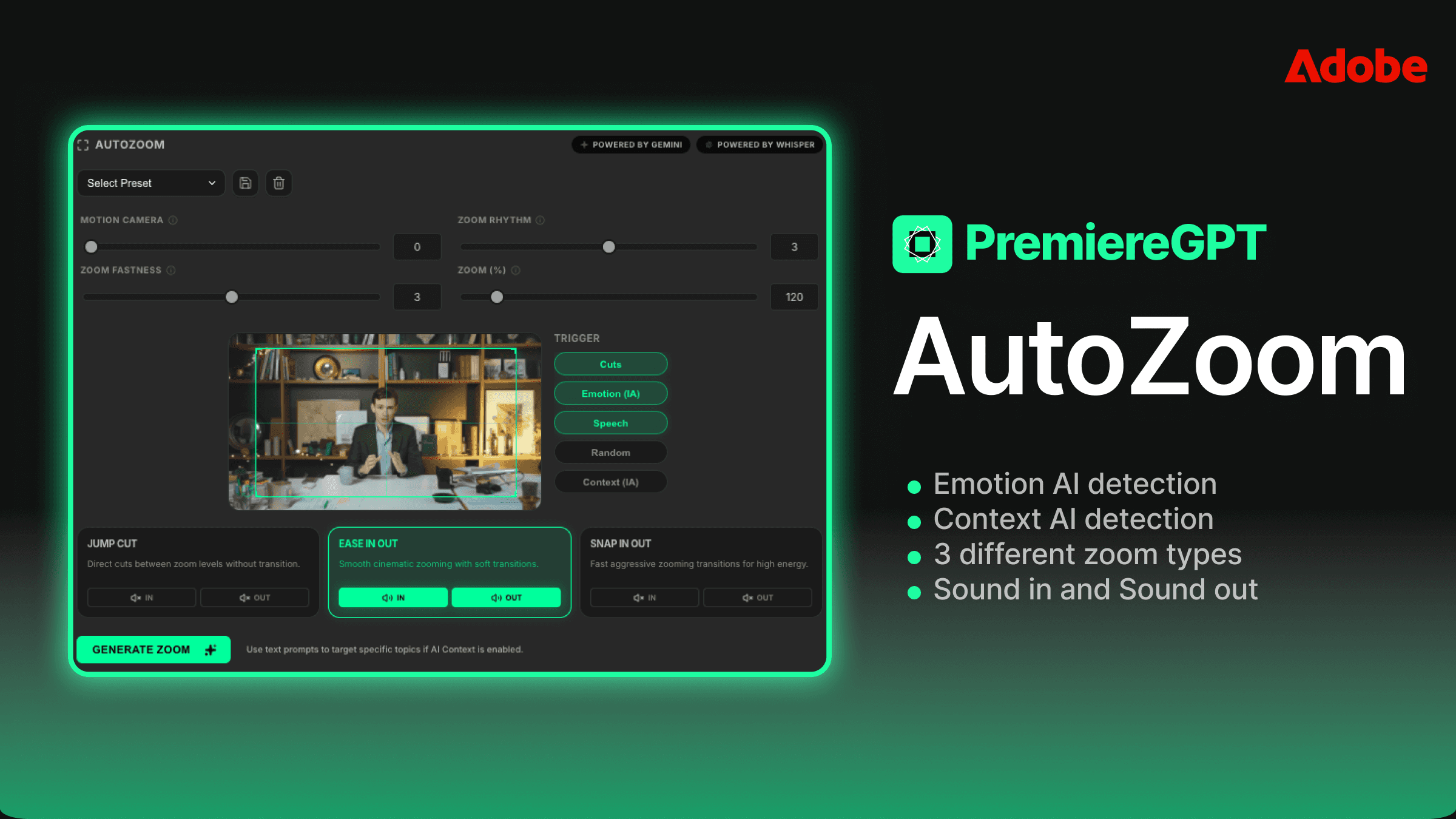
ワークフロー:マスターシーケンスからローカライズ済み書き出しまで3クリック
正しくセットアップしたときの、実際のPremiere内ワークフローはこうなります。ブラウザのタブなし。ファイルの書き出しなし。クリップボードでの曲芸なし。
マスターシーケンスを仕上げます。ピクチャーロック、オーディオミックス、グラフィックの最終化。プラグインパネルを開く——テキストパネルと同じワークスペースに、好きな場所にドッキングして配置されています。マスターシーケンスはすでにソースとして選択済み。ステップ1:言語リストからターゲット言語を選ぶ。言語セットをプリセットとして保存できるので、いつもスペイン語・フランス語・ドイツ語を納品するなら、それはワンクリックの選択です。
ステップ2:修正プロンプトを適用する。プロジェクトタイプ別のテンプレートを保存してあれば、ドロップダウンから選ぶだけ。新しいプロジェクトタイプなら、用意したプロンプトを貼り付ける。いずれにせよ30秒もかかりません。
ステップ3:プロセスを実行する。Whisperがシーケンスから直接音声を取り込みます——書き出し不要です。プラグインがAPI経由でPremiereのタイムラインから音声を読み取るからです。GPT-5.3が、あなたのプロンプトを使って各ターゲット言語に対してトランスクリプトを処理します。出力はSRTファイルのセットと、オプションで、ISO言語コードでラベル付けされてプロジェクトのビンに自動的に読み込まれるキャプショントラックです。
そこから先は、ローカライズ済みシーケンスにキャプショントラックを適用するのはドラッグ&ドロップの操作です。言語ごとに別々の書き出しを納品するなら、マスターシーケンスを複製し、対応するキャプショントラックを適用して書き出す。字幕ストリームを埋め込んだ1ファイルを納品するなら、SRTはすでにそのワークフロー用に整形されています。
設定済みのワークフローにとって、3クリックという説明は誇張ではありません。セットアップ時間はプロンプトテンプレートと言語プリセットの作成に前倒しされ、それは一度きりです。それ以降のプロジェクトごとの実行は、本当にその速さです。
SRT書き出しと自動読み込みのベストプラクティス
クリーンなSRT出力には、見落としやすく、後工程で直すのが面倒ないくつかの技術パラメータへの注意が必要です。
1行あたりの文字数制限は、納品プラットフォームや視聴コンテキストによって異なります。放送字幕の規格は通常1行37文字・最大2行が上限です。オンラインプラットフォームはより寛容で——YouTubeやVimeoはほとんどの画面サイズで1行42文字を表示の問題なく扱えます——しかしそれを超えるとモバイルで可読性の問題が生じます。文字数制限は処理の後ではなく前に、書き出し設定で指定しましょう。後から字幕タイミングを短い行長に合わせて再整形するのは、かなりの手作業になります。
読み速度は、プロの字幕とアマチュアの字幕を分けるもう一つのタイミングパラメータです。成人視聴者の標準は毎秒17文字です。より若い視聴者向けや教育的な文脈では、毎秒13文字が安全です。GPT-5.3の翻訳は言語ペアによってはソースより長くなることがあります——ドイツ語やフィンランド語は大きく膨らむ複合語で悪名高い——ので、読み速度チェックを書き出し検証の一部に組み込めば、クライアントの修正依頼になる前にタイミング違反を捕まえられます。
Premiereへの自動読み込みのために、SRTファイルにはビンに格納される前にISO 639-1の言語コードを接尾辞として付けましょう。projectname_es.srt、projectname_fr.srt、projectname_de.srt。この命名規則は、特に10以上の言語納品物を扱うプロジェクトで、バッチ操作やシーケンスのラベル付けを大幅にすっきりさせます。
ローカライズ済みキャプションのフォント安全性は、多くのエディターがつまずく別の問題です。カスタムフォントを使ったキャプションプリセットは、あなたのマシンでは正しく表示されても、そのフォントがインストールされていない他のすべてのマシンでは崩れます。クライアントが独立して使うSRT納品物では、システム標準のフォントに留めるか、納品仕様にフォント情報を明示的に記載しましょう。焼き込み(バーン)ではこれはあまり問題になりませんが、いずれにせよ納品メモにフォントの選択を記録しておきましょう。
マスターシーケンスとSRTタイミングの間のフレームレート整合は、妥協できません。29.97fpsのタイムラインに対して生成されたSRTは、25fpsのシーケンスに対してずれていきます。文字起こしプロセスを実行する前にシーケンスのフレームレートを確認し、書き出し前にもう一度確認しましょう。20分の動画の終わりまでに0.5秒ずれるキャプショントラックを防ぐ、30秒のチェックです。
ローカライズ業務をスケールさせているエディターは、手作業を増やしているわけではありません。同じ作業を一度だけ行い、その出力を増幅するシステムを使っているのです。ブラウザの往復は単に遅いだけではなく、扱えるローカライズのボリュームに上限を設ける構造的なボトルネックです。そのボトルネックを取り除けば、ボリュームの天井は消えます。
このワークフローをさらに進めたいなら、まさにこういう納品シナリオ向けの実用的なリファレンス文書を用意しました。グローバルクリエイターの書き出しチェックリストは、フレームレートの互換性、プラットフォーム別の文字数制限、国際文字セットのためのフォント安全性をカバーし、グローバル納品向けに作られた5つのすぐ使えるキャプションプリセットを含みます。ローカライズ済みの書き出しを準備するたびに、セカンドモニターに開いておくべきリファレンスシートです。下からダウンロードして、国際プロジェクトのたびにこの情報をゼロから組み立て直すのをやめましょう。