Die Retention-Edit-Falle: Warum manuelle Punch-ins deinen Stundensatz ruinieren
Du kennst diesen Schnitt. Talking-Head-Material. Eine Kamera. Der Kunde will, dass es sich „dynamisch" anfühlt – energiegeladen, knackig, gebaut für kurze Aufmerksamkeitsspannen. Also setzt du dich hin und machst die Sache. Du schaust dir einen Satz an, setzt einen Keyframe auf die Skalierung-Eigenschaft, ziehst sie um 15 % hoch, easest sie rein, easest sie raus, schubst den Abspielkopf, wiederholst. Bei einem 10-minütigen Interview kommst du auf irgendwo zwischen 40 und 80 einzelne Zoom-Momente. Das sind Hunderte von Keyframes. Von Hand.
Das ist die Retention-Edit-Falle. Der Stil wurde durch eine Welle hochfrequenter Social-Inhalte populär – die Art, bei der sich alle drei Sekunden visuell etwas ändert, damit der Daumen des Zuschauers stillsteht. Es funktioniert. Das Problem sind die Arbeitskosten. Wenn du einen Pauschalpreis pro Video berechnest und vier Stunden allein mit Punch-ins verbringst, verlierst du aktiv Geld, jedes Mal, wenn du diese Sequenz öffnest.
Und das Schlimmste? Die meisten dieser Zooms sind willkürlich. Du reagierst nicht auf die Sprechweise des Sprechers. Du füllst nur Raum mit Bewegung, weil sich der Schnitt zu statisch anfühlt. Du wendest eine Technik ohne echten Auslöser an, was bedeutet, dass sich das Ergebnis ohnehin oft mechanisch anfühlt – Zooms, die auf der falschen Silbe landen, Punch-ins, die während eines Atemzugs statt einer Pointe treffen.
Es gibt einen besseren Weg, das zu tun, und er beginnt damit, die Frage wann man zoomt von der Frage wie man es umsetzt zu trennen. Der erste Teil – das Wann – ist eigentlich ein Datenproblem. Und Datenprobleme lassen sich automatisieren.
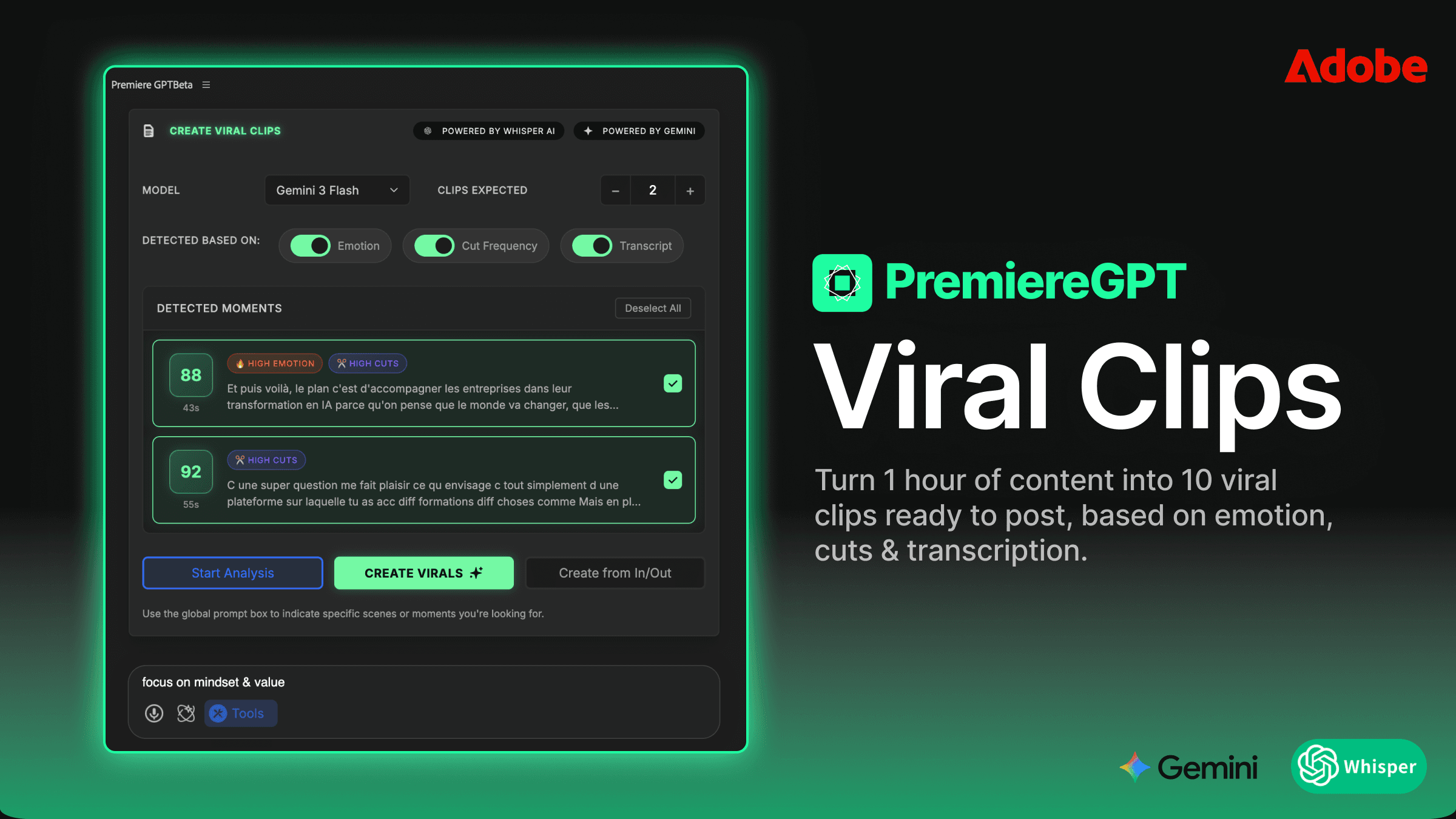
Emotionserkennung vs. statische Mathematik: Wie der Algorithmus 'Peak'-Momente für einen Zoom identifiziert
Die meisten einfachen Auto-Zoom-Plugins arbeiten mit statischer Mathematik. Sie schauen auf die Audioamplitude, finden die lautesten Transienten und setzen einen Zoom auf diese Frames. Es ist ein grobes Werkzeug. Laut bedeutet nicht wichtig. Ein Sprecher, der sich räuspert, ist laut. Ein Klatschen auf den Tisch ist laut. Der eigentliche Moment emotionaler Betonung – die Pause vor dem Schlüsselwort, der leichte Tonhöhenanstieg bei einer entscheidenden Phrase – das sind oft nicht die lautesten Momente in der Wellenform. Es sind die bedeutungsvollsten Momente, und die Amplitude allein kann sie nicht finden.
Emotionserkennung arbeitet auf einer anderen Ebene. Statt nur das Audiosignal zu lesen, analysiert sie den Sprachinhalt, die Prosodie (Rhythmus, Betonung und Intonation der Sprache) und das semantische Gewicht des Gesagten. Der Algorithmus stellt eine grundlegend andere Frage. Er fragt nicht „Wo ist der Audio-Peak?" Er fragt „Wo ist der Sprecher bei der höchsten emotionalen Intensität?"
In der Praxis bedeutet das, dass das System Momente identifizieren kann, in denen ein Sprecher zu einer Schlussfolgerung hinführt, eine rhetorische Frage landet, ein Moment der Verletzlichkeit oder Betonung – die Art von Beats, die ein erfahrener Cutter beim Ansehen des Materials instinktiv spüren würde. Die KI sieht das Material nicht, aber sie parst dieselben Signale, auf die ein versierter Cutter reagieren würde: Tonwechsel, Pacing-Änderung, semantischer Höhepunkt.
Das Ergebnis ist eine Zoom-Platzierung, die tatsächlich dem Erzählbogen des Sprechers folgt, statt nur den lautesten Treffern in der Audiodatei. Wenn du die KI-generierten Effekte in deiner Timeline prüfst, wirst du feststellen, dass die Punch-ins auf Momenten landen, die du selbst gewählt hättest – das heißt weniger Zeit zum Korrigieren schlechter Platzierungen und mehr Zeit für die wenigen Anpassungen, die wirklich redaktionelles Urteilsvermögen erfordern.
Das ist keine Magie. Es ist eine gut abgegrenzte Automatisierungsaufgabe. Der Algorithmus trifft keine kreativen Entscheidungen – er bringt die Momente an die Oberfläche, die statistisch am ehesten von einer visuellen Betonung profitieren. Du entscheidest weiterhin, ob diese Betonung für das konkrete Stück richtig ist. Aber jetzt triffst du diese Entscheidung bei 10 % der Zooms, statt 100 % davon von Grund auf zu setzen.
Über den Crop hinaus: Geschwindigkeit, Sounddesign und KI-Kontext-Prompts für den perfekten 'Vibe' anpassen
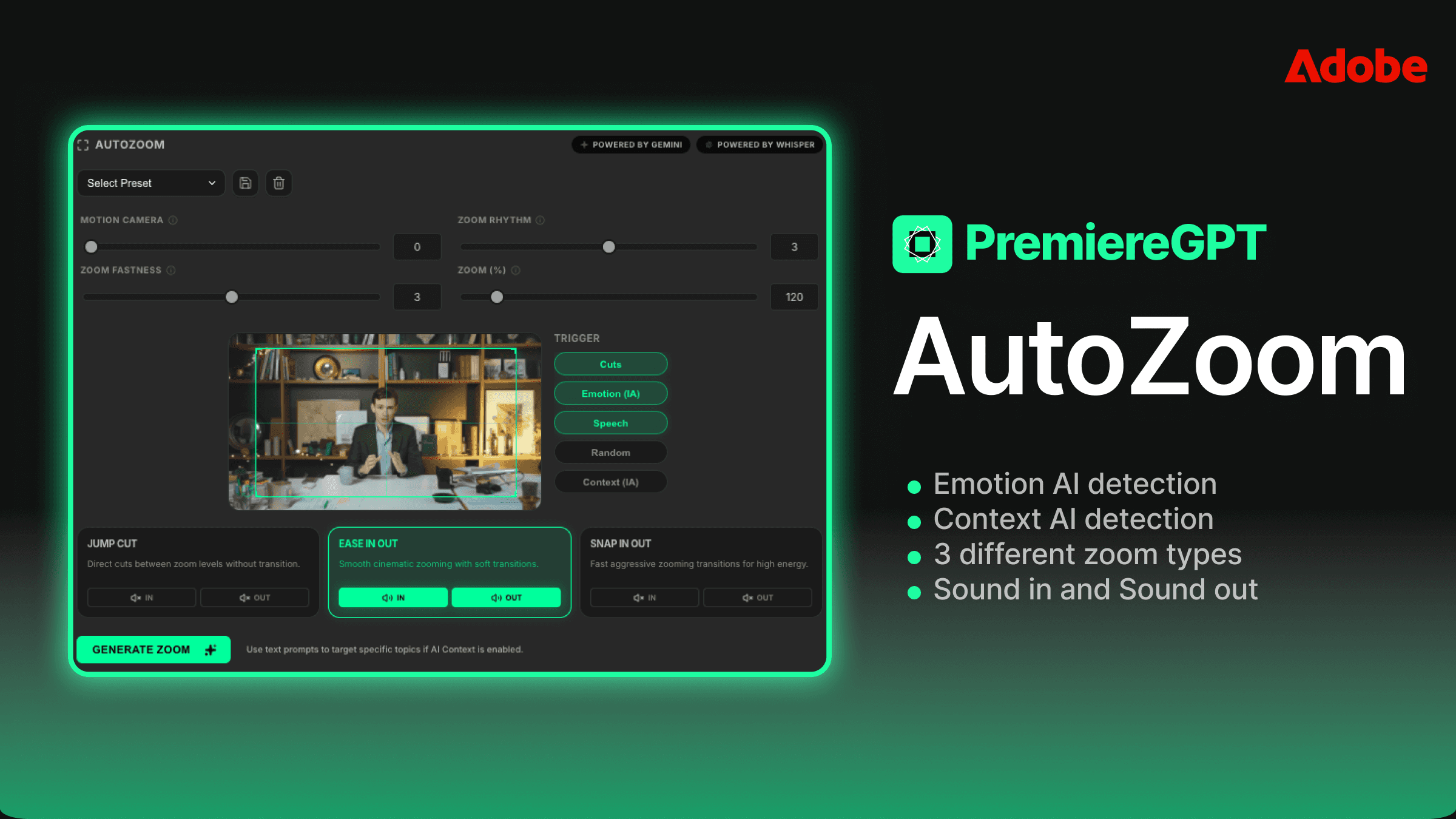
Ein Zoom ist nicht einfach nur ein Zoom. Der Unterschied zwischen einem 4-Frame-Punch-in mit einem Whoosh-Sound und einem 12-Frame-Smooth-Push ohne Audiobearbeitung ist der Unterschied zwischen einem Hype-Reel und einer Dokumentation. Geschwindigkeit und Sounddesign sind die Variablen, die das emotionale Register eines Retention-Edits definieren, und jedes ernstzunehmende Automatisierungstool muss dir Kontrolle über beide geben.
Beim Konfigurieren deiner Auto-Zoom-Durchläufe arbeitest du mit zwei primären Geschwindigkeitsprofilen. Schnelle Zooms – typischerweise 3 bis 6 Frames – sind deine energiegeladenen Schnitte. Sie funktionieren für motivierende Inhalte, Reaktionsmomente, Pointen. Sie wirken aggressiv und das sollen sie auch. Smooth-Zooms – 10 bis 20 Frames mit geeaster Interpolation – sind für erzählerische Inhalte, emotionale Beats, erklärende Segmente, bei denen du den Zuschauer hineinziehen statt aufschrecken willst. Das falsche Geschwindigkeitsprofil im richtigen Moment ist trotzdem ein schlechter Schnitt.
Das Layern von Sounddesign auf Zooms wird oft als Nebensache behandelt, ist aber tatsächlich eines der wirkungsvollsten Elemente im Retention-Edit-Stack. Ein subtiler tieffrequenter Schlag unter einem langsamen Push verleiht Gewicht. Ein knappes hochfrequentes Swish unter einem schnellen Punch-in verleiht Snap. Die Audiobearbeitung sagt dem Gehirn des Zuschauers, wie es sich zur visuellen Bewegung fühlen soll, bevor er sie bewusst verarbeitet hat.
Die KI-Kontext-Prompt-Funktion ist der Punkt, an dem der Workflow wirklich raffiniert wird. Statt einen Einheits-Zoom-Algorithmus anzuwenden, kannst du dem System eine kurze Beschreibung der emotionalen Intention des Inhalts geben. Ein Prompt wie „motivierender Business-Content, hohe Energie, selbstbewusster Sprecher" kalibriert die Erkennungsschwelle anders als „persönliche Geschichte, emotionale Verletzlichkeit, langsames Pacing". Der Algorithmus nutzt den Kontext, um zu gewichten, welche emotionalen Signale bei der Auswahl der Zoom-Auslösepunkte priorisiert werden.
Stell es dir vor wie das Briefen der KI, so wie du einen Junior-Cutter briefen würdest. Du gibst ihr kein Frame-für-Frame-Skript – du gibst ihr genug Kontext, um innerhalb ihres operativen Rahmens bessere Entscheidungen zu treffen. Je spezifischer dein Prompt, desto mehr spiegelt das Ergebnis den tatsächlichen Ton des Stücks wider statt eine generische Retention-Edit-Vorlage.
Non-destruktiver Workflow: Warum Zooms auf Effektebenen verschachtelten Sequenzen jedes Mal überlegen sind
Hier ist der Teil, der aus professioneller Workflow-Sicht am meisten zählt, und es ist der Teil, der ein Tool, das es wert ist, benutzt zu werden, von einem Tool trennt, das mehr Probleme schafft, als es löst.
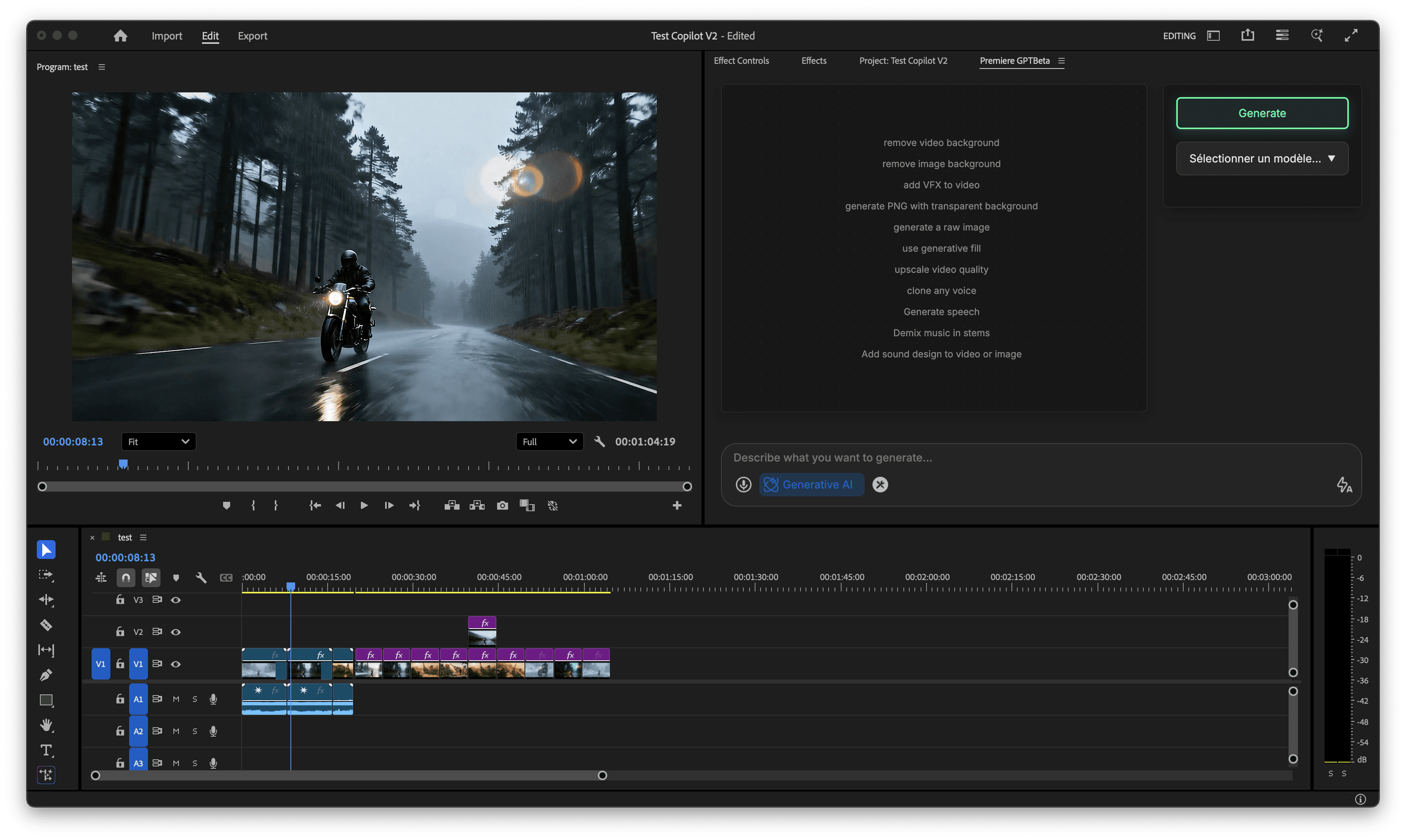
Wenn PremiereCopilot Auto-Zooms auf deine Timeline anwendet, brennt es die Bewegung nicht in deine Clips ein. Es verschachtelt dein Material nicht. Es fasst deine Originalmedien nicht an. Es wendet die Zoom-Effekte als Effektebenen an – dedizierte Ebenen im Einstellungsebenen-Stil, die über deinem Material in der Timeline liegen und alle vom KI-Durchlauf generierten Skalierung- und Position-Keyframes enthalten.
Warum ist das wichtig? Weil verschachtelte Sequenzen eine Falle sind. Sobald du einen Clip verschachtelst, um Bewegung darauf anzuwenden, hast du eine Abstraktionsebene zwischen dir und deinem Schnitt eingefügt. Musst du den Clip trimmen? Jetzt verwaltest du In- und Out-Punkte über zwei Ebenen der Timeline hinweg. Musst du das zugrunde liegende Material austauschen? Du gehst in die Verschachtelung. Musst du den Zoom ganz entfernen? Du löschst entweder die Verschachtelung oder gehst hinein. Jeder Vorgang, der einfach sein sollte, wird zu einem zweistufigen Prozess.
Effektebenen halten alles auf derselben Timeline-Tiefe. Der Zoom liegt auf einer Ebene über dem Clip. Du kannst ihn sehen, auswählen, löschen, verschieben oder seine Keyframes direkt im Effekteinstellungen-Panel anpassen – genau so, wie du mit jedem anderen Effekt in Premiere Pro arbeiten würdest. Die KI hat die Schwerstarbeit von Platzierung und Timing geleistet, aber du hast 100 % redaktionelle Kontrolle über jeden einzelnen generierten Zoom. Nichts ist gesperrt. Nichts ist in einer Verschachtelung versteckt.
Diese Architektur bedeutet auch, dass die Zooms vollständig portabel sind. Wenn du einen Clip in der Timeline verschieben musst, bewegt sich die Effektebene mit ihm. Wenn du eine Zoom-Behandlung von einem Segment auf ein anderes kopieren willst, kopierst du eine Ebene und duplizierst nicht eine verschachtelte Sequenz mit all dem Overhead, den das mit sich bringt.
Für Cutter, die hochvolumigen Social-Content machen – mehrere Schnitte pro Woche, mehrere Seitenverhältnisse, schnelle Revisionszyklen –, ist dieser non-destruktive Ansatz kein Nice-to-have. Es ist der einzige Workflow, der skaliert, ohne technische Schulden in deinen Projektdateien zu erzeugen.
So richtest du deine AutoZoom-Presets für 10x schnellere Social-Cuts ein
Der echte Effizienzgewinn beim KI-gestützten Zoomen kommt nicht von einem einzelnen Durchlauf bei einem einzelnen Video. Er kommt vom Aufbau einer Preset-Bibliothek, die deinen spezifischen Schnittstil und die spezifischen Content-Typen deiner Kunden widerspiegelt. So strukturierst du dieses System.
Schritt eins: Definiere deine Content-Kategorien. Die meisten Cutter im Social-Content-Bereich schneiden über eine Handvoll wiederkehrender Content-Typen – motivierender/Business-Content, Lern-Erklärvideos, persönliches Storytelling, Interview-/Podcast-Clips. Jeder davon hat eine andere optimale Zoom-Dichte (wie viele Zooms pro Minute), ein anderes Geschwindigkeitsprofil und eine andere Sounddesign-Behandlung. Dokumentiere diese, bevor du deine Presets baust.
Schritt zwei: Baue deine Baseline-Presets pro Kategorie. Konfiguriere für jeden Content-Typ ein Preset mit deiner Zoom-Dichte-Einstellung, deinem Geschwindigkeitsprofil (schnell vs. smooth), deiner bevorzugten Sounddesign-Ebene und deinem Standard-KI-Kontext-Prompt. Benenne diese Presets klar – „Business Motivational - High Energy", „Podcast Clip - Conversational", „Story - Emotional". Wenn ein neues Projekt reinkommt, wählst du ein Preset aus, statt deine Einstellungen von Grund auf neu zu bauen.
Schritt drei: Führe den KI-Durchlauf aus und mache einen einzigen Review-Durchgang. Nachdem der Auto-Zoom gelaufen ist und die Effektebenen in deiner Timeline platziert sind, mache einen fokussierten Review-Durchgang. Du baust nichts auf – du entfernst nur Zooms, die nicht funktionieren, und passt gelegentlich das Timing bei denen an, die nah dran, aber nicht exakt sind. Bei einem gut konfigurierten Preset, das auf passenden Content angewendet wird, solltest du weniger als 20 % der generierten Zooms entfernen oder anpassen. Wenn du mehr als das anpasst, braucht dein Preset Verfeinerung, nicht mehr Handarbeit.
Schritt vier: Iteriere deine Prompts auf Basis der Ergebnisse. Führe eine laufende Notiz darüber, welche KI-Kontext-Prompts für jeden Content-Typ die beste Zoom-Platzierung erzeugt haben. Mit der Zeit entwickelst du ein Prompt-Vokabular, das auf deine spezifischen Kunden und Content-Stile abgestimmt ist. Das ist die sich verzinsende Rendite des Systems – jedes Video, das du schneidest, macht deine Presets etwas genauer, was etwas weniger Review-Arbeit beim nächsten bedeutet.
Schritt fünf: Baue deine Social-Cut-Varianten aus demselben Effektebenen-Stack. Wenn du ein 16:9-Langformat und einen 9:16-Short aus demselben Material schneidest, lassen sich deine Effektebenen anpassen statt neu aufbauen. Die Zoom-Positionen und das Timing sind bereits etabliert – du passt Skalierungswerte und Ankerpunkte für die Neukadrierung an, statt den gesamten KI-Durchlauf von Grund auf neu auszuführen.
Die kumulierte Zeitersparnis über einen Monat Social-Content-Arbeit ist erheblich. Wir reden davon, von vier Stunden manueller Zoom-Arbeit pro Video auf unter 45 Minuten Konfiguration, Review und Verfeinerung zu kommen. Das ist keine Schätzung aus einem Marketing-Deck – das ist die Rechnung, Hunderte manueller Keyframes durch einen einzigen KI-Durchlauf und einen fokussierten redaktionellen Review zu ersetzen.
Das Ziel war nie, den Cutter aus dem Prozess zu entfernen. Das Ziel ist, die mechanischen Teile des Prozesses zu entfernen, damit die Zeit des Cutters für Entscheidungen aufgewendet wird, die wirklich Urteilsvermögen erfordern.
Wenn du immer noch bei jedem Talking-Head-Schnitt manuell Skalierung-Eigenschaften keyframest, schneidest du nicht – du machst Dateneingabe. Die Technik hat ihren Platz, aber die Ausführung sollte überall dort automatisiert werden, wo die Automatisierung genau genug ist, um ihr zu vertrauen. Mit Emotionserkennung, die die Platzierung steuert, und Effektebenen, die deine Kontrolle bewahren, ist sie es.
Bereit, nicht mehr jedes Mal Zoom-Presets von Grund auf zu bauen? Lade das Retention-Editing-Cheat-Sheet herunter – ein praktischer PDF-Leitfaden, der genau abdeckt, wann man Fast- vs. Smooth-Zoom-Profile verwendet, eine kuratierte Liste von KI-Kontext-Prompts, geordnet nach Content-Typ, und eine Zoom-Dichte-Referenztabelle für die gängigsten Social-Formate. Alles, was du brauchst, um deinen ersten KI-gestützten Zoom-Durchlauf zu konfigurieren und Ergebnisse zu erzielen, die du tatsächlich im Schnitt behältst.