O pesadelo do 'Checkerboard': por que separar áudio manualmente é uma relíquia
Você já passou por isso. Abre um novo projeto de podcast e o cliente envia um único arquivo WAV estéreo da chamada de Zoom. Três apresentadores, quarenta e cinco minutos, uma única faixa. Seu primeiro trabalho, antes de tocar em qualquer edição, é descobrir quem disse o quê e colocar cada voz em sua própria faixa de áudio dedicada. Isso é o checkerboarding, e em 2024 ainda é um processo quase totalmente manual dentro do Premiere Pro.
O checkerboarding — a prática de escalonar clipes em várias faixas para que cada locutor fique em A1, A2 ou A3 — é o passo fundamental de qualquer mixagem de podcast séria. Você não consegue aplicar um EQ específico por locutor sem isso. Não consegue definir limiares de compressão independentes sem isso. Não consegue automatizar níveis por voz sem isso. Todo fluxo de trabalho profissional depende dessa separação e, ainda assim, o editor não-linear padrão do mercado continua sem uma única ferramenta nativa para fazer isso automaticamente.
O resultado é que os editores fazem uma de duas coisas: passam quarenta e cinco minutos varrendo uma timeline e cortando clipes manualmente com a ferramenta lâmina para novas faixas, ou terceirizam o problema para ferramentas externas e depois reimportam os resultados, quebrando a timeline nativa e destruindo qualquer chance de um round-trip limpo. Nenhuma das opções é aceitável para um editor de podcast de alto volume que entrega três ou quatro programas por semana.
A dívida técnica das gravações em faixa única
O problema de raiz está mais acima na cadeia. As configurações de gravação remota — Zoom, Riverside, SquadCast e até alguns mixers de hardware — frequentemente colapsam várias entradas em um único arquivo intercalado antes mesmo de chegar ao seu disco. Mesmo quando os clientes gravam localmente e enviam arquivos individuais, um número surpreendente deles envia um bounce estéreo mixado por desconhecimento. Essa dívida técnica cai na sua timeline.
Quando tudo está em uma única faixa, seu gain staging fica comprometido desde o início. Um locutor está alto, outro está baixo, outro tem um microfone USB com um pico de 3 kHz. Aplicar uma única instância de compressor às três vozes simultaneamente não é mixar — é controle de danos. O compressor fica bombeando o tempo todo porque está reagindo a três perfis dinâmicos completamente diferentes de uma vez. Seu limitador captura os picos do locutor mais alto enquanto o mais baixo fica soterrado. A única solução real é a separação, e a única forma real de chegar lá com eficiência é a automação.
O que é diarização de locutores (e por que isso não está nativamente no Premiere Pro)?
A diarização de locutores é o processo de particionar um fluxo de áudio em segmentos de acordo com a identidade de quem fala. O algoritmo escuta uma gravação, identifica assinaturas vocais distintas e rotula cada segmento: "O locutor 1 falou de 00:00 a 00:47, o locutor 2 de 00:47 a 01:15", e assim por diante. É um campo bem estabelecido no áudio computacional — empresas de telefonia usam isso para análises de call center há mais de uma década.
Então por que isso não está no Premiere Pro? A resposta honesta é que as prioridades de desenvolvimento da Adobe estiveram em outro lugar. O recurso Speech to Text que chegou ao Premiere é genuinamente útil para edição baseada em transcrição, mas foi construído em torno de um caso de uso diferente: encontrar palavras em uma timeline, não separar locutores em faixas. O painel de Transcrição da Adobe pode rotular locutores depois do fato, mas esse rótulo vive em um campo de metadados. Ele não move um único clipe. Não cria uma nova faixa. Não toca na sua timeline de forma alguma.
É aí que está a lacuna. E ela é significativa.
Transcrição vs. diarização: conhecendo a diferença
Esses dois termos são constantemente confundidos, e a confusão leva os editores a achar que o problema já está resolvido quando não está. A transcrição converte fala em texto. A diarização identifica e separa locutores. São processos relacionados, mas produzem resultados fundamentalmente diferentes.
Uma ferramenta de transcrição diz a você: "Em 2:34, alguém disse 'Acho que o problema real é a largura de banda'." Uma ferramenta de diarização diz a você: "O segmento de 2:34 a 2:41 pertence ao locutor 2, e aqui está esse segmento de áudio como um objeto discreto e movível." O primeiro é um documento. O segundo é uma ação editorial.
O Speech to Text da Adobe, mesmo com seu recurso de rotulagem de locutores, está firmemente na primeira categoria. Ele gera uma transcrição com marcações de locutor. O que ele não faz é pegar o clipe de áudio em A1, cortá-lo em segmentos e distribuir esses segmentos por A1, A2 e A3 com base em quem está falando. Essa reorganização física da timeline é o que a diarização-como-ferramenta-editorial realmente significa, e é exatamente o que falta no conjunto de recursos nativos do Premiere.
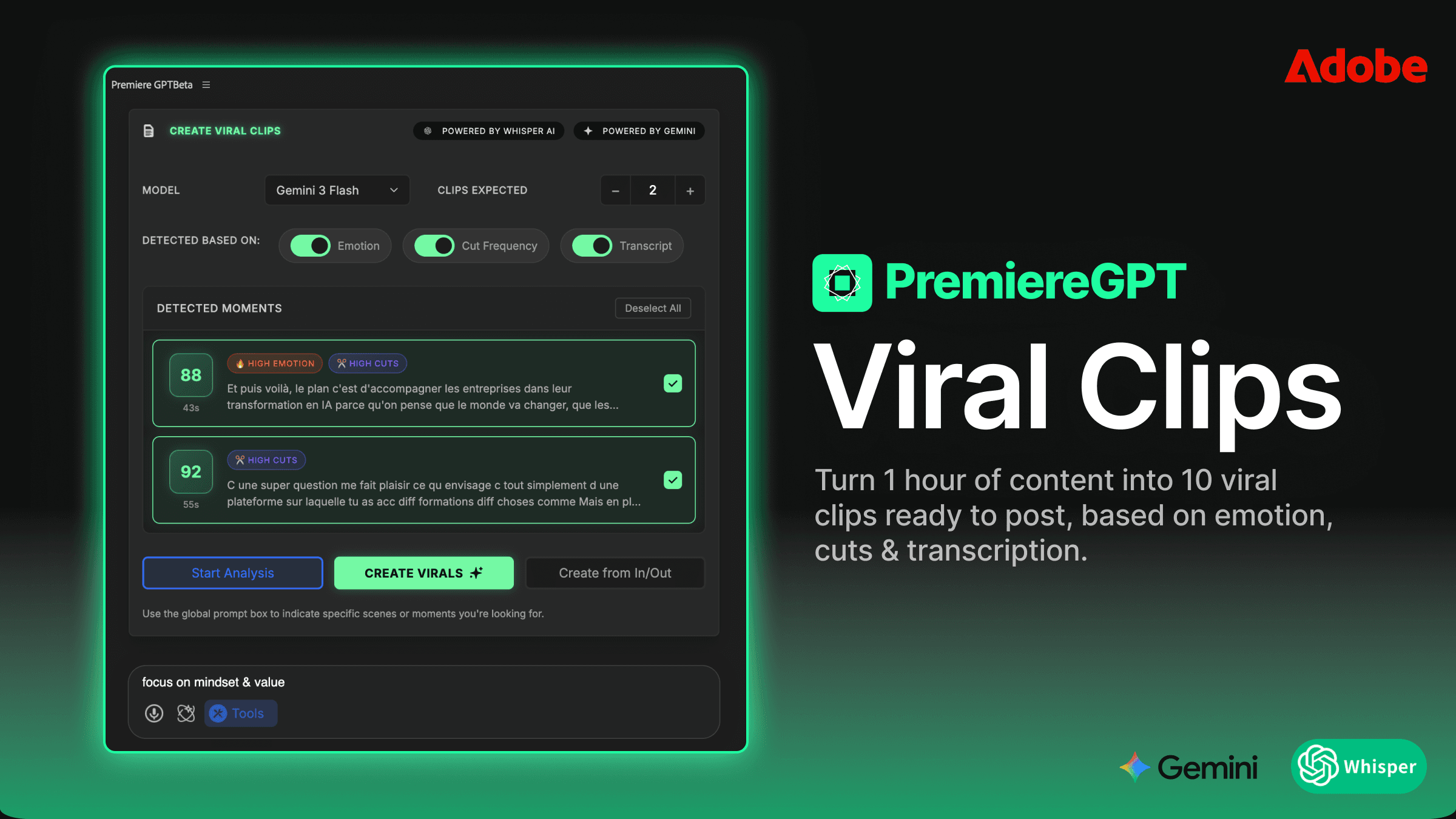
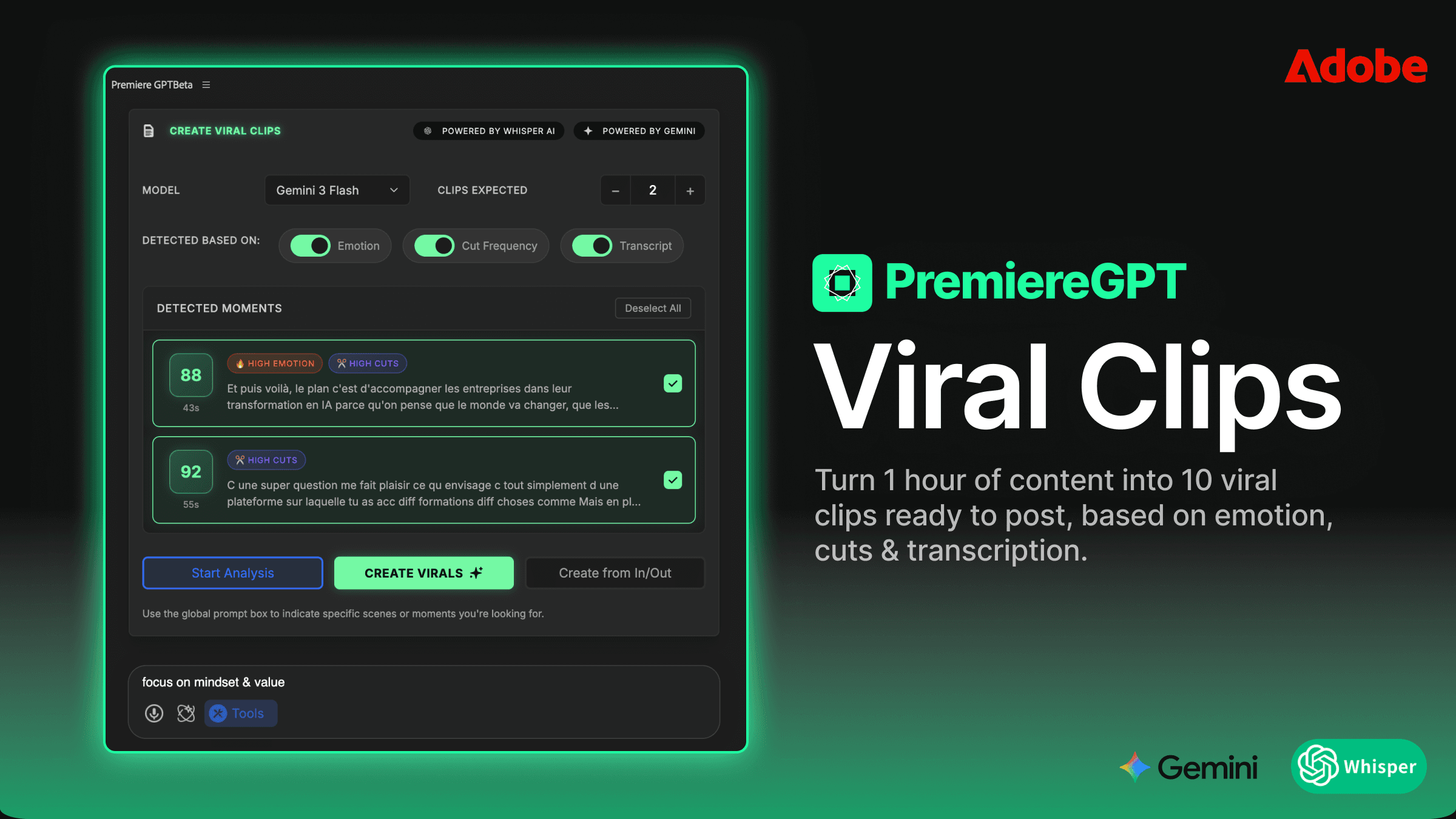
Como o Smart Diarization funciona: de uma para dez faixas em 5 minutos
A única ferramenta que atualmente lida com a verdadeira separação de locutores no nível da timeline dentro do Premiere Pro é a extensão Smart Diarization. Não é um fluxo de trabalho de round-trip em que você exporta, processa externamente e reimporta. A extensão opera diretamente na sua sequência, lê o áudio do clipe selecionado, executa o modelo de diarização e então cria fisicamente novas faixas e as preenche com os segmentos corretamente atribuídos — tudo sem você sair da timeline.
O processo funciona assim: você seleciona o clipe de áudio mixado na sua timeline, aciona a extensão, define o número esperado de locutores e deixa rodar. Quando termina, seu clipe único em A1 foi substituído por um conjunto de faixas — uma por locutor identificado — com os segmentos de áudio apropriados dispostos em checkerboard entre elas. Os clipes já estão sincronizados com a posição original na timeline. Sua faixa de vídeo permanece intacta. O timecode da sua sequência fica preservado.
O que torna isso tecnicamente relevante é que a separação acontece no nível do clipe na timeline do Premiere, e não em um aplicativo separado. Os clipes resultantes são clipes de áudio padrão do Premiere. Você pode aplicar configurações do Mixer de Faixas de Áudio, soltar plugins VST diretamente em cada faixa, definir gain staging independente por faixa e automatizar níveis exatamente como faria com qualquer layout multifaixa montado manualmente. O fluxo de trabalho que você já conhece se aplica imediatamente.
Suportando até 10 locutores sem sair da timeline
Para um podcast padrão com dois apresentadores, a diarização já é uma economia de tempo significativa. Mas o verdadeiro valor fica evidente em mesas-redondas, gravações de painéis ou capturas de sessões de conferência onde você pode ter cinco, seis ou até dez vozes distintas em um único arquivo. Fazer o checkerboarding manual de uma gravação com dez locutores não é um trabalho de quarenta e cinco minutos. É um trabalho de meio dia, e é o tipo de tarefa que faz os editores questionarem suas escolhas de carreira.
O Smart Diarization suporta até dez locutores simultâneos em uma única passagem. Você define a contagem de locutores antes do processamento, e o algoritmo particiona de acordo. Cada locutor recebe sua própria faixa dedicada na sequência do Premiere. Se você está trabalhando na gravação de um debate político, numa town hall corporativa ou num programa de entrevistas com vários convidados, essa é a diferença entre um fluxo de trabalho que escala e um que não escala.
A detecção de locutores é baseada na modelagem da assinatura vocal, não na separação de canais. Isso significa que funciona em mixagens mono verdadeiras e em arquivos estéreo colapsados — exatamente os formatos que causam mais dor de cabeça nas entregas do mundo real. Você não precisa de um arquivo de origem multicanal limpo para que isso funcione. Você precisa do único arquivo problemático que seu cliente de fato enviou.
Passo a passo: configurando seus assets e caminhos para uma organização limpa
Antes de rodar a diarização em qualquer coisa, sua estrutura de projeto precisa estar configurada para receber a saída de forma limpa. Despejar clipes gerados automaticamente em um bin de projeto desorganizado é uma forma de criar outro tipo de bagunça. Aqui está um protocolo de configuração limpa para projetos de podcast.
Primeiro, estabeleça sua estrutura de bins antes de importar. Crie uma pasta de projeto principal com sub-bins dedicados: Áudio Bruto, Clipes Diarizados, Música e SFX, e Sequências. Quando o processo de diarização cria novos clipes, eles precisam de um lar designado. A maioria das extensões exporta os clipes para um caminho especificado — conheça esse caminho antes de começar e garanta que ele aponte para o seu bin de Clipes Diarizados.
Segundo, ajuste as configurações da sua sequência para corresponder à sua entrega de áudio. Se você está entregando um podcast estéreo a 48kHz/24-bit, as configurações de áudio da sua sequência devem refletir isso antes de começar a separar faixas. Rodar a diarização e depois descobrir que sua sequência está configurada para 44.1kHz é um problema solucionável, mas desnecessário.
Terceiro, nomeie suas faixas imediatamente após a diarização terminar. O Premiere permite renomear faixas de áudio diretamente no painel da timeline. No momento em que seus clipes estiverem distribuídos de A1 a A4, renomeie essas faixas: Apresentador 1, Apresentador 2, Convidado, Coapresentador — o que fizer sentido para o seu programa específico. É um passo de trinta segundos que evita muita confusão durante a mixagem, especialmente se você voltar a um projeto depois de um dia afastado.
Quarto, faça uma verificação de sincronia antes de iniciar qualquer processamento. Coloque um ponto de referência — uma palma, uma contagem regressiva, qualquer transiente acentuado que todos os locutores teriam ouvido ao mesmo tempo — e confirme que seus clipes diarizados estão corretamente posicionados em relação ao seu vídeo ou áudio de referência. A diarização funciona sobre o conteúdo do áudio, não sobre o timecode absoluto, então uma rápida verificação visual contra uma referência de forma de onda é uma boa prática antes de partir para a mixagem.
Quinto, crie um snapshot da sequência pré-mixagem. Duplique sua sequência antes de aplicar qualquer plugin VST ou processamento de faixa. Rotule-a com o sufixo _PRE-MIX. Essa é a sua rede de segurança. Se um plugin introduzir problemas de compensação de latência ou se você precisar revisitar as separações brutas, você tem um ponto de restauração limpo que não exige rodar a diarização de novo.
Além da separação: como a diarização possibilita melhor mixagem e processamento
Colocar os locutores em faixas separadas não é o objetivo final. É o pré-requisito para tudo o que realmente importa em uma mixagem profissional de podcast. Uma vez que você tem faixas discretas por locutor, toda a sua cadeia de sinal se torna intencional em vez de reativa.
Considere o gain staging. Em um layout multifaixa devidamente diarizado, você ajusta o ganho de entrada de cada faixa de forma independente para atingir um nível-alvo consistente antes que qualquer processamento de dinâmica toque nele. O Apresentador 1 grava alto, com média de -6 dBFS — você reduz o ganho da faixa. O Convidado grava baixo, a -24 dBFS — você aumenta o ganho da faixa. Agora cada locutor atinge seu compressor aproximadamente no mesmo nível de entrada, e seu compressor pode fazer o trabalho de verdade: controlar a dinâmica, não compensar níveis de origem extremamente inconsistentes.
Essa é a diferença entre uma mixagem que soa como uma produção profissional e uma que soa como uma gravação bruta com um alvo de loudness jogado por cima. A diarização torna possível um gain staging adequado. Sem ela, você está chutando.
Aplicando VSTs específicos por locutor e normalização de níveis
Com os locutores em faixas separadas, a atribuição de plugins VST se torna cirúrgica. É aqui que está o verdadeiro valor de produção, e é o fluxo de trabalho que separa os editores que entendem de áudio dos que apenas apertam exportar.
Uma cadeia típica de processamento específico por locutor no Mixer de Faixas de Áudio do Premiere pode ser assim: um filtro passa-alta para limpar o ronco de graves (a frequência de corte vai variar por locutor e por microfone), um EQ dinâmico para tratar as ressonâncias específicas da voz e da sala daquele locutor, um compressor ajustado à faixa dinâmica e à cadência de fala daquele locutor e um limitador final ajustado ao seu teto. Cada uma dessas configurações depende do locutor. O apresentador com um microfone condensador numa sala tratada precisa de uma curva de EQ completamente diferente da do convidado remoto com um headset USB numa cozinha.
O aninhamento de VST é particularmente poderoso aqui. Se você usa plugins de terceiros como FabFilter Pro-Q 3, iZotope RX ou plugins da Waves, pode aninhar uma cadeia inteira de processamento em cada faixa de locutor e salvá-la como um preset. No próximo episódio, mesmo programa, mesmos locutores — você carrega o preset, sua cadeia de processamento volta ao lugar e você está mixando minutos depois de abrir o projeto. Esse tipo de consistência de sessão para sessão só é possível quando você tem atribuições de faixa consistentes, o que só é possível quando você tem uma separação de locutores confiável.
A normalização de níveis por locutor é o outro grande benefício. Rodar a normalização de loudness embutida da Adobe, ou uma ferramenta de terceiros como o Auphonic, em faixas de locutor individuais em vez de em um barramento mixado dá resultados muito mais precisos. O algoritmo de normalização está analisando uma voz por vez, não tentando achar um alvo médio entre três perfis vocais completamente diferentes. A saída é mais consistente, e você gasta menos tempo movimentando faders para compensar os pontos cegos da normalização.
Teste de desempenho: computação local vs. alternativas baseadas na nuvem
Qualquer conversa séria sobre ferramentas de diarização para uso em produção precisa abordar a questão do desempenho. Você tem duas opções de arquitetura: o processamento local, em que o modelo de diarização roda na sua máquina, e o processamento baseado na nuvem, em que seu áudio é enviado para um servidor remoto e os resultados retornam de forma assíncrona.
As ferramentas baseadas na nuvem — e há várias que fazem uma diarização competente — introduzem uma série de problemas que são impeditivos para ambientes de produção profissional. O tempo de upload de um arquivo de áudio de quarenta e cinco minutos em uma conexão de banda larga padrão não é trivial. Esperar uma fila na nuvem processar seu trabalho não é um custo de tempo previsível. E para editores que lidam com conteúdo confidencial — podcasts corporativos, processos jurídicos, entrevistas sensíveis — enviar o áudio do cliente para um servidor de terceiros é frequentemente uma violação contratual. Essas não são preocupações teóricas. São restrições operacionais reais.
A computação local resolve tudo isso. O Smart Diarization roda seu modelo na sua máquina local, o que significa que o tempo de processamento é função do seu hardware, não da fila de um servidor compartilhado. Em um Mac moderno com Apple Silicon ou uma estação de trabalho Windows com uma CPU capaz, um episódio de podcast de quarenta e cinco minutos é processado em bem menos de cinco minutos. Sem upload. Sem fila. Sem dados saindo da sua máquina. O áudio permanece no seu projeto, no seu disco, sob o seu controle.
O trade-off é que modelos locais exigem recursos locais. A diarização é computacionalmente intensiva — você está rodando uma rede neural sobre um fluxo de áudio. Em hardware mais antigo, os tempos de processamento serão maiores. Mas mesmo em hardware modesto, o processamento local é mais rápido que a alternativa manual, e as vantagens de privacidade e confiabilidade são inegociáveis para uso profissional.
As ferramentas de nuvem também tendem a entregar sua saída como uma transcrição rotulada ou um conjunto de arquivos de áudio exportados — o que te traz de volta ao problema da reimportação em round-trip. Você volta a posicionar clipes manualmente nas faixas, o que anula o propósito da automação. A diarização local, integrada à timeline, não é apenas mais rápida. Ela é arquiteturalmente superior para o fluxo de trabalho editorial real dentro do Premiere Pro.
O objetivo nunca foi rotular quem disse o quê. O objetivo sempre foi colocar cada voz em sua própria faixa para que você pudesse de fato mixar o programa. Todo o resto é uma solução pela metade.
A diarização de locutores como conceito existe no mundo da engenharia de áudio há anos. O que faltava era a implementação que vive onde os editores realmente trabalham — dentro da timeline, operando sobre clipes, produzindo resultados que alimentam diretamente a mixagem. Essa lacuna agora pode ser fechada e, para editores de podcast de alto volume, fechá-la não é opcional. É a única forma de manter uma operação de produção sustentável com qualidade profissional.
Se você está pronto para dar o próximo passo e realmente usar essas faixas separadas para construir uma mixagem de podcast de classe mundial, montamos exatamente o framework para fazer isso. Baixe o Podcast Mixing Blueprint — um guia prático detalhando as curvas de EQ específicas, as configurações de compressão e os alvos de gain staging para aplicar a cada faixa de locutor depois que sua diarização estiver pronta. É o guia de processamento que pega exatamente de onde o fluxo de separação para. Baixe o Podcast Mixing Blueprint e experimente o Smart Diarization hoje mesmo.