「チェッカーボード」の悪夢:手動の音声トラック分割が時代遅れの遺物である理由
あなたも経験があるはずです。新しいポッドキャストのプロジェクトを開くと、クライアントがZoom通話からの1つのステレオWAVファイルを送ってくる。ホスト3人、45分、トラック1本。最初の仕事は、1つの編集に手をつける前に、誰が何を言ったかを把握し、それぞれの声を専用の音声トラックに乗せることです。これがチェッカーボーディングであり、2024年になってもPremiere Proの中ではいまだにほぼ完全に手作業のプロセスなのです。
チェッカーボーディング——各話者がA1、A2、A3に存在するように複数のトラックにクリップをずらして配置する手法——は、本格的なポッドキャストミックスの基礎となるステップです。それなしには話者ごとのEQを適用できません。それなしには独立したコンプレッションのしきい値を設定できません。それなしには声ごとにレベルを自動化できません。あらゆるプロのワークフローがこの分離に依存しているにもかかわらず、業界標準のNLEはいまだにそれを自動で行うネイティブツールを1つも搭載せずに出荷されているのです。
その結果、編集者は2つのうちどちらかをしています:45分かけてタイムラインをスクラブし、手動でクリップをレーザーカットして新しいトラックに乗せるか、問題を外部ツールに外注してから結果を再インポートし、ネイティブのタイムラインを壊してクリーンなラウンドトリップの可能性を破壊するか。どちらの選択肢も、週に3〜4本の番組を回す大量処理のポッドキャスト編集者には受け入れられません。
シングルトラック録音の技術的負債
根本的な問題は上流にあります。リモート録音のセットアップ——Zoom、Riverside、SquadCast、一部のハードウェアミキサーでさえ——は、ドライブに届く前に複数の入力を1つのインターリーブされたファイルにまとめてしまうことが多いのです。クライアントがローカルで録音して個別のファイルを送ってくる場合でさえ、驚くほど多くの人が、よく知らないがゆえにミックスダウンされたステレオバウンスを送ってきます。その技術的負債があなたのタイムラインに着地するのです。
すべてが1つのトラックにあると、ゲインステージングは最初から損なわれています。1人の話者は音が大きく、1人は静かで、1人は3 kHzで鳴るUSBマイクを使っている。3つの声すべてに同時に1つのコンプレッサーを適用するのはミキシングではありません——それはダメージコントロールです。コンプレッサーは3つのまったく異なるダイナミックプロファイルに同時に反応するため、絶えずポンピングします。リミッターは最も大きい話者のピークを捉える一方で、最も静かな話者は埋もれたままになります。唯一の本当の解決策は分離であり、そこに効率的にたどり着く唯一の本当の方法は自動化です。
話者分離とは何か(そしてなぜPremiere Proにネイティブで搭載されていないのか)?
話者分離とは、話者の同一性に従ってオーディオストリームをセグメントに分割するプロセスです。アルゴリズムは録音を聞き、明確な声の特徴を識別し、各セグメントにラベルを付けます:「話者1は00:00から00:47まで話していた、話者2は00:47から01:15まで」というように。これは計算オーディオの分野で確立された領域です——電話会社は10年以上にわたってコールセンターの分析にこれを使ってきました。
では、なぜPremiere Proに搭載されていないのでしょうか?正直な答えは、Adobeの開発優先順位が別のところにあったということです。Premiereに搭載された文字起こし機能は、文字起こしベースの編集には本当に役立ちますが、それは異なるユースケースを中心に作られていました:話者をトラックに分離するのではなく、タイムライン上で単語を見つけることです。Adobeの文字起こしパネルは後から話者にラベルを付けられますが、そのラベルはメタデータフィールドの中に存在します。それは1つのクリップも動かしません。新しいトラックも作りません。あなたのタイムラインにはまったく触れないのです。
これがそのギャップです。そしてそれは重大なギャップなのです。
文字起こし vs. 話者分離:違いを知る
この2つの用語は絶えず混同され、その混乱は編集者に、まだ解決されていない問題がすでに解決済みだと思い込ませます。文字起こしは音声をテキストに変換します。話者分離は話者を識別して分離します。それらは関連するプロセスですが、根本的に異なる出力を生み出します。
文字起こしツールはこう教えてくれます:「2:34に、誰かが『本当の問題は帯域幅だと思う』と言った。」話者分離ツールはこう教えてくれます:「2:34から2:41までのセグメントは話者2のもので、これがその音声セグメントを個別の、移動可能なオブジェクトとして提示したものです。」前者はドキュメントです。後者は編集上のアクションです。
Adobeの文字起こしは、話者ラベリング機能を備えていてもなお、しっかりと前者のカテゴリーに属します。それは話者タグ付きの文字起こしを生成します。それがしないのは、A1の音声クリップを取り、それをセグメントに切り分け、誰が話しているかに基づいてそれらのセグメントをA1、A2、A3に分配することです。そのタイムラインの物理的な再編成こそが、編集ツールとしての話者分離が実際に意味するものであり、まさにそれがPremiereのネイティブ機能セットに欠けているものなのです。
Smart Diarizationの仕組み:1トラックから10トラックへ5分で
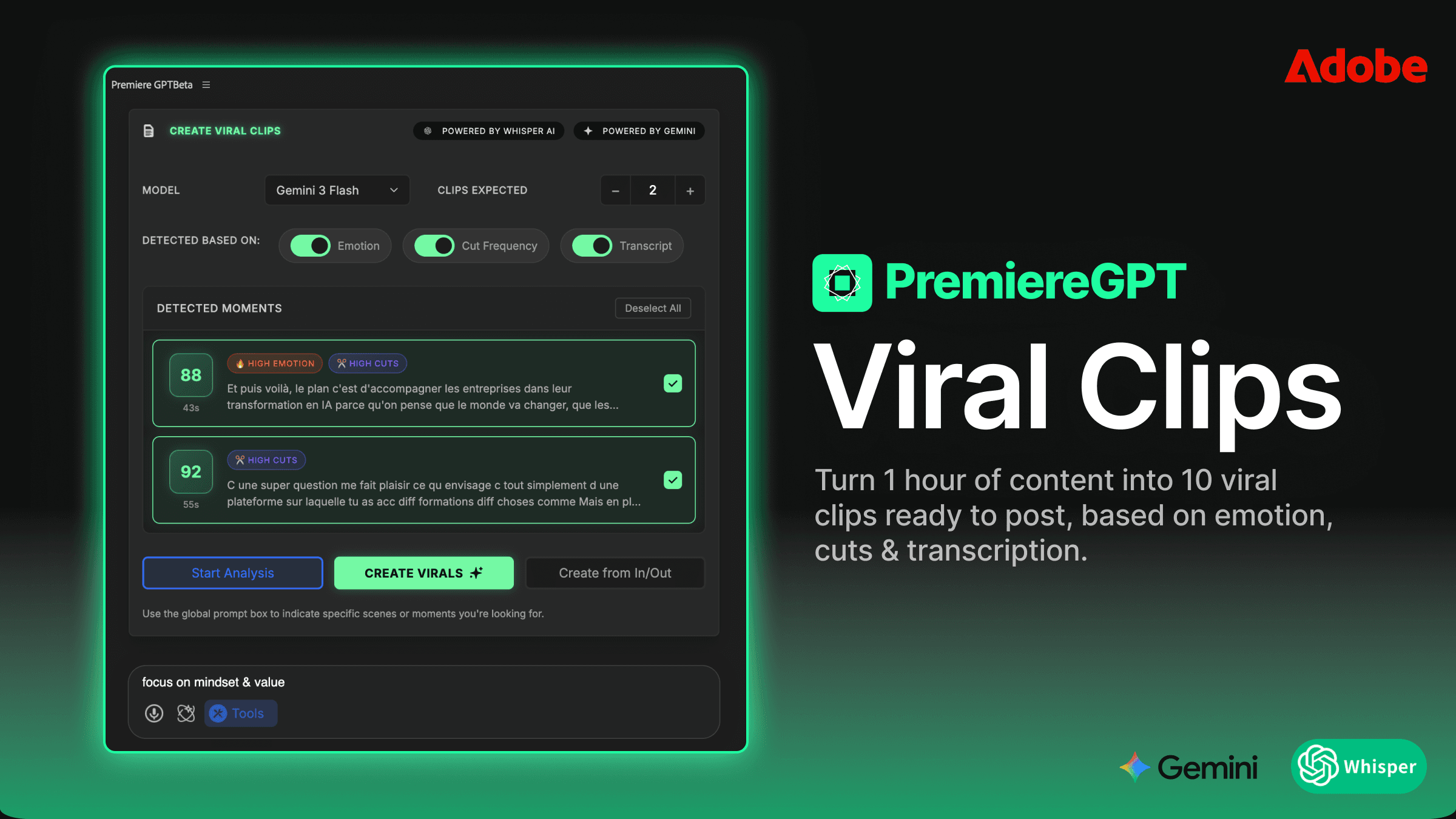
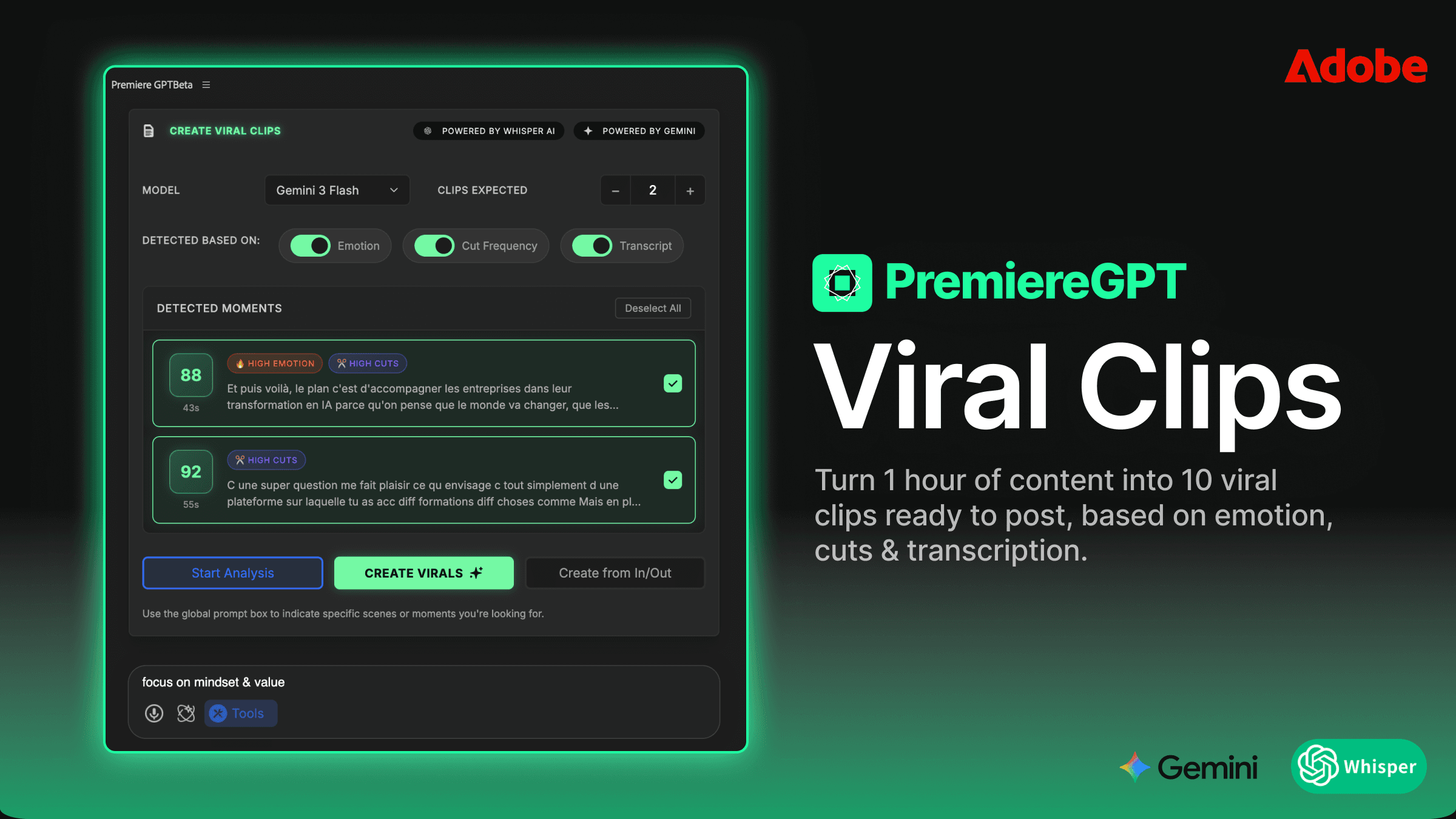
現在、Premiere Proの中で真のタイムラインレベルの話者分割を扱う唯一のツールが、Smart Diarization拡張機能です。これは、書き出して、外部で処理し、再インポートするラウンドトリップのワークフローではありません。拡張機能はあなたのシーケンス上で直接動作し、選択したクリップから音声を読み取り、話者分離モデルを実行し、そして物理的に新しいトラックを作成して正しく帰属されたセグメントをそれらに配置します——すべてタイムラインを離れることなく。
プロセスはこのように動きます:タイムライン上のミックスされた音声クリップを選択し、拡張機能を起動し、想定される話者数を設定して、実行させる。終わると、A1上のあなたの1つのクリップが一連のトラック——識別された話者ごとに1つ——に置き換えられ、適切な音声セグメントがそれらにチェッカーボード状に配置されています。クリップはすでに元のタイムライン位置と同期しています。ビデオトラックは触れられていません。シーケンスのタイムコードはそのままです。
これを技術的に意味あるものにしているのは、分割が別個のアプリケーションではなく、Premiereのタイムラインのクリップレベルで起こるということです。結果として得られるクリップは標準的なPremiereの音声クリップです。オーディオトラックミキサーの設定を適用し、各トラックに直接VSTプラグインをドロップし、トラックごとに独立したゲインステージングを設定し、手動で組み立てたマルチトラックレイアウトとまったく同じようにレベルを自動化できます。あなたがすでに知っているワークフローがすぐに適用できるのです。
タイムラインを離れずに最大10人の話者をサポート
標準的な2ホストのポッドキャストでも、話者分離はすでに大幅な時間の節約です。しかし本当の価値が明らかになるのは、1つのファイルに5人、6人、あるいは10人もの明確な声がいるかもしれないパネルディスカッション、円卓録音、カンファレンスセッションのキャプチャです。10人の話者の録音を手動でチェッカーボーディングするのは、45分の仕事ではありません。半日の仕事であり、編集者にキャリアの選択を疑わせる類の作業です。
Smart Diarizationは、1回のパスで最大10人の同時話者をサポートします。処理の前に話者数を設定すると、アルゴリズムがそれに応じて分割します。各話者がPremiereシーケンスの中で自分専用のトラックを得ます。政治討論の録音、企業のタウンホール、複数ゲストのインタビュー番組に取り組んでいるなら、これはスケールするワークフローと、しないワークフローとの違いです。
話者検出はチャンネル分離ではなく、声の特徴のモデリングに基づいています。これはつまり、真のモノラルミックスや崩れたステレオファイル——現実の納品物で最も苦痛を引き起こすまさにそのフォーマット——で機能するということです。これが機能するためにクリーンなマルチチャンネルのソースファイルは必要ありません。クライアントが実際に送ってきた、その1つの問題のあるファイルが必要なのです。
ステップバイステップ:クリーンな整理のためにアセットとパスを設定する
何かに対して話者分離を実行する前に、出力をクリーンに受け取れるようプロジェクト構造を設定する必要があります。自動生成されたクリップを散らかったプロジェクトビンに放り込むのは、別の種類の混乱を生み出す方法です。ポッドキャストプロジェクトのためのクリーンなセットアッププロトコルがこちらです。
まず、インポート前にビン構造を確立しましょう。専用のサブビンを持つマスタープロジェクトフォルダを作成します:Raw Audio、Diarized Clips、Music and SFX、そしてSequences。話者分離のプロセスが新しいクリップを作成するとき、それらには指定された住所が必要です。ほとんどの拡張機能は指定されたパスにクリップを出力します——始める前にそのパスを把握し、それがDiarized Clipsビンにマッピングされていることを確認しましょう。
次に、シーケンス設定を音声の納品物に合わせましょう。48kHz/24-bitのステレオポッドキャストを納品するなら、トラックの分割を始める前にシーケンスのオーディオ設定がそれを反映しているべきです。話者分離を実行してからシーケンスが44.1kHzに設定されていることに気づくのは、直せる問題ですが、不必要な問題です。
3つ目に、話者分離が完了したらすぐにトラックにラベルを付けましょう。Premiereではタイムラインパネルで直接音声トラックの名前を変更できます。クリップがA1からA4に分配された瞬間に、それらのトラックの名前を変更します:Host 1、Host 2、Guest、Co-host——あなたの特定の番組にマッピングされるものなら何でも。これはミックス中の混乱を大幅に減らす30秒のステップで、特に1日離れてからプロジェクトに戻る場合に効果的です。
4つ目に、処理を始める前に同期チェックを行いましょう。基準点——拍手、カウントダウン、すべての話者が同時に聞いたであろう鋭いトランジェント——を置き、分離されたクリップがビデオや基準オーディオに対して正しく配置されていることを確認します。話者分離は絶対的なタイムコードではなく音声内容に対して機能するので、ミックスに進む前に波形の基準に対して素早く視覚的にチェックするのは良い習慣です。
5つ目に、ミックス前のシーケンスのスナップショットを作成しましょう。VSTプラグインやトラック処理を適用する前にシーケンスを複製します。接尾辞_PRE-MIXでラベルを付けます。これがあなたのセーフティネットです。プラグインがレイテンシー補正の問題を引き起こしたり、生の分割を見直す必要が出たりした場合、話者分離のプロセスを再実行する必要のないクリーンな復元ポイントがあります。
分割を超えて:話者分離がより良いミキシングと処理を可能にする方法
話者を別々のトラックに乗せることが最終目標ではありません。それは、プロのポッドキャストミックスで実際に重要なすべての前提条件です。話者ごとに個別のトラックを得ると、あなたのシグナルチェーン全体が反応的なものではなく目的を持ったものになります。
ゲインステージングを考えてみましょう。適切に分離されたマルチトラックレイアウトでは、ダイナミクス処理が触れる前に一貫した目標レベルに到達するよう、各トラックの入力ゲインを独立して設定します。Host 1は平均-6 dBFSで大きく録音されている——トラックゲインを下げる。Guestは-24 dBFSで静かに録音されている——トラックゲインを上げる。これで、すべての話者がほぼ同じ入力レベルでコンプレッサーに到達し、コンプレッサーは本来の仕事をできます:大きくばらついたソースレベルを補正するのではなく、ダイナミクスをコントロールすること。
これが、プロの制作のように聞こえるミックスと、ラウドネスターゲットを貼り付けただけの生の録音のように聞こえるミックスとの違いです。話者分離は適切なゲインステージングを可能にします。それなしでは、あなたは推測しているのです。
話者ごとのVSTとレベルノーマライゼーションを適用する
話者が別々のトラックにいると、VSTプラグインの割り当てが外科手術的になります。ここに本当の制作価値が宿り、それが音声を理解する編集者と、ただ書き出しを押すだけの編集者を分けるワークフローです。
Premiereのオーディオトラックミキサーにおける典型的な話者ごとの処理チェーンはこのようになるかもしれません:低域のランブルをクリアにするハイパスフィルター(カットオフ周波数は話者ごと、マイクごとに異なります)、その話者の声と部屋の特定の共鳴に対処するダイナミックEQ、その話者のダイナミックレンジと話すリズムに合わせて調整されたコンプレッサー、そしてあなたの上限に設定された最終リミッター。これらの設定の1つ1つが話者依存です。音響処理された部屋でコンデンサーマイクを使うホストは、キッチンでUSBヘッドセットを使うリモートゲストとはまったく異なるEQカーブを必要とします。
ここではVSTのネスティングが特に強力です。FabFilter Pro-Q 3、iZotope RX、Wavesプラグインのようなサードパーティのプラグインを使っているなら、各話者トラックに処理チェーン全体をネストし、それをプリセットとして保存できます。次のエピソード、同じ番組、同じ話者——プリセットを読み込めば、処理チェーンが元の場所に戻り、プロジェクトを開いてから数分でミキシングしています。この種のセッション間の一貫性は、一貫したトラックの割り当てがあるときにのみ可能であり、それは信頼できる話者分離があるときにのみ可能なのです。
話者ごとのレベルノーマライゼーションがもう1つの大きな利点です。Adobeの組み込みのラウドネスノーマライゼーション、あるいはAuphonicのようなサードパーティのツールを、ミックスされたバスではなく個々の話者トラックで実行すると、はるかに正確な結果が得られます。ノーマライゼーションのアルゴリズムは、3つのまったく異なる声のプロファイルにまたがる平均的なターゲットを見つけようとするのではなく、一度に1つの声を分析しています。出力はより一貫し、ノーマライゼーションの盲点を補うためにフェーダーを操作する時間が減ります。
パフォーマンスチェック:ローカル計算 vs. クラウドベースの代替手段
制作用途の話者分離ツールについての本格的な会話は、どれもパフォーマンスの問題に向き合わなければなりません。あなたには2つのアーキテクチャの選択肢があります:話者分離モデルがあなたのマシン上で動作するローカル処理と、あなたの音声がリモートサーバーにアップロードされ結果が非同期で返されるクラウドベースの処理です。
クラウドベースのツール——そして有能な話者分離を行うものはいくつかあります——は、プロの制作環境にとって致命的な一連の問題を持ち込みます。標準的なブロードバンド接続での45分の音声ファイルのアップロード時間は些細なものではありません。クラウドのキューがあなたのジョブを処理するのを待つのは予測可能な時間コストではありません。そして機密性の高いコンテンツに取り組む編集者——企業のポッドキャスト、法的手続き、デリケートなインタビュー——にとって、クライアントの音声をサードパーティのサーバーにアップロードすることは、しばしば契約違反です。これらは理論上の懸念ではありません。現実の運用上の制約です。
ローカル計算はこれらすべてを解決します。Smart Diarizationはモデルをあなたのローカルマシン上で実行します。つまり処理時間は共有サーバーのキューではなく、あなたのハードウェアの関数なのです。最新のApple Silicon Macや有能なCPUを持つWindowsワークステーションでは、45分のポッドキャストエピソードは5分を大きく下回って処理されます。アップロードなし。キューなし。データがあなたのマシンを離れることなし。音声はあなたのプロジェクトの中、あなたのドライブ上、あなたのコントロールの下に留まります。
トレードオフは、ローカルモデルがローカルリソースを必要とすることです。話者分離は計算集約的です——あなたは音声ストリームに対してニューラルネットワークを実行しているのです。古いハードウェアでは処理時間は長くなります。しかし控えめなハードウェアでも、ローカル処理は手動の代替手段より速く、プライバシーと信頼性の利点はプロの用途には譲れないものです。
クラウドツールはまた、出力をラベル付きの文字起こしや一連の書き出された音声ファイルとして提供する傾向があります——これがあなたをラウンドトリップのインポート問題に引き戻します。あなたは手動でクリップをトラックに配置することに戻り、自動化の目的を打ち消します。ローカルでタイムラインに統合された話者分離は、単に速いだけではありません。Premiere Pro内の実際の編集ワークフローにとって、アーキテクチャ的に優れているのです。
目標は誰が何を言ったかにラベルを付けることでは決してありませんでした。目標は常に、各声を自分自身のトラックに乗せて、実際に番組をミックスできるようにすることでした。それ以外はすべて中途半端な解決策です。
話者分離という概念は、音声エンジニアリングの世界で何年も存在してきました。欠けていたのは、編集者が実際に働く場所——タイムラインの中、クリップを操作し、ミックスに直接つながる結果を生み出す——に存在する実装です。そのギャップは今や埋められるようになり、大量処理のポッドキャスト編集者にとって、それを埋めることは選択肢ではありません。それがプロ品質で持続可能な制作運営を回す唯一の方法なのです。
次のステップに進み、分離されたトラックを実際に使って世界クラスのポッドキャストミックスを構築する準備ができたなら、私たちはそれを行うための正確なフレームワークをまとめました。Podcast Mixing Blueprintをダウンロードしましょう——話者分離が終わった後、各話者トラックに適用する具体的なEQカーブ、コンプレッション設定、ゲインステージングのターゲットを詳述した実用的なチートシートです。それは分割のワークフローが終わるまさにその場所から引き継ぐ処理ガイドです。Podcast Mixing Blueprintをダウンロードして、今日Smart Diarizationを試してみましょう。