Le cauchemar du 'Checkerboard' : Pourquoi la séparation audio manuelle est une relique
Vous connaissez cette situation. Vous ouvrez un nouveau projet de podcast et le client vous envoie un seul fichier WAV stéréo provenant de son appel Zoom. Trois hôtes, quarante-cinq minutes, une seule piste. Votre premier travail, avant même de toucher au montage, est de déterminer qui a dit quoi et de placer chaque voix sur sa propre piste audio dédiée. C'est le "checkerboarding" (disposition en damier), et en 2024, c'est encore un processus presque entièrement manuel dans Premiere Pro.
Le checkerboarding — la pratique consistant à échelonner les clips sur plusieurs pistes pour que chaque intervenant réside sur A1, A2 ou A3 — est l'étape fondamentale de tout mixage de podcast sérieux. Vous ne pouvez pas appliquer d'égalisation (EQ) spécifique à un intervenant sans cela. Vous ne pouvez pas définir de seuils de compression indépendants sans cela. Vous ne pouvez pas automatiser les niveaux par voix sans cela. Chaque flux de travail professionnel dépend de cette séparation, et pourtant, le logiciel de montage de référence du marché est toujours livré sans le moindre outil natif pour le faire automatiquement.
Le résultat est que les monteurs font l'une des deux choses suivantes : passer quarante-cinq minutes à parcourir une timeline et à couper manuellement des clips sur de nouvelles pistes, ou externaliser le problème vers des outils tiers puis réimporter les résultats, cassant la timeline native et détruisant toute chance d'un flux de travail propre. Aucune de ces options n'est acceptable pour un monteur de podcast à haut volume traitant trois ou quatre émissions par semaine.
La dette technique des enregistrements sur piste unique
Le problème racine se situe en amont. Les configurations d'enregistrement à distance — Zoom, Riverside, SquadCast, même certains mélangeurs matériels — compressent souvent plusieurs entrées en un seul fichier entrelacé avant même qu'il n'atteigne votre disque. Même lorsque les clients enregistrent localement et vous envoient des fichiers individuels, un nombre surprenant d'entre eux envoient un export stéréo mixé par méconnaissance. Cette dette technique atterrit sur votre timeline.
Quand tout est sur une seule piste, votre gain staging est compromis dès le départ. Un intervenant est trop fort, un autre trop faible, un autre a un micro USB avec une résonance à 3 kHz. Appliquer une seule instance de compresseur aux trois voix simultanément n'est pas du mixage — c'est du sauvetage. Le compresseur pompe constamment car il réagit à trois profils dynamiques complètement différents à la fois. Votre limiteur attrape les pics de l'intervenant le plus fort pendant que le plus discret reste enterré. La seule vraie solution est la séparation, et le seul moyen d'y parvenir efficacement est l'automatisation.
Qu'est-ce que la diarisation des intervenants (et pourquoi n'est-elle pas native dans Premiere Pro ?)
La diarisation des intervenants est le processus de partitionnement d'un flux audio en segments selon l'identité du locuteur. L'algorithme écoute un enregistrement, identifie les signatures vocales distinctes et étiquette chaque segment : "L'intervenant 1 parlait de 00:00 à 00:47, l'intervenant 2 de 00:47 à 01:15", etc. C'est un domaine bien établi dans l'audio computationnel — les sociétés de téléphonie l'utilisent pour l'analyse des centres d'appels depuis plus d'une décennie.
Alors pourquoi n'est-ce pas dans Premiere Pro ? La réponse honnête est que les priorités de développement d'Adobe ont été ailleurs. La fonction Speech to Text arrivée dans Premiere est utile pour le montage basé sur la transcription, mais elle a été conçue pour un autre cas d'usage : trouver des mots dans une timeline, pas séparer les intervenants sur des pistes. Le panneau Transcription d'Adobe peut étiqueter les intervenants après coup, mais cette étiquette vit dans un champ de métadonnées. Elle ne déplace aucun clip. Elle ne crée pas de nouvelle piste. Elle ne touche pas du tout à votre timeline.
C'est là que se situe le fossé. Et il est significatif.
Transcription vs Diarisation : Connaître la différence
Ces deux termes sont constamment confondus, ce qui laisse croire aux monteurs que le problème est déjà résolu. La transcription convertit la parole en texte. La diarisation identifie et sépare les locuteurs. Ce sont des processus liés, mais ils produisent des résultats fondamentalement différents.
Un outil de transcription vous dit : "À 2:34, quelqu'un a dit 'Je pense que le vrai problème est la bande passante'." Un outil de diarisation vous dit : "Le segment de 2:34 à 2:41 appartient à l'intervenant 2, et voici ce segment audio en tant qu'objet distinct et déplaçable." Le premier est un document. Le second est une action éditoriale.
Le Speech to Text d'Adobe, même avec sa fonction d'étiquetage, appartient fermement à la première catégorie. Il génère une transcription. Ce qu'il ne fait pas, c'est prendre le clip audio sur A1, le couper en segments et distribuer ces segments sur A1, A2 et A3 selon qui parle. Cette réorganisation physique de la timeline est ce que signifie réellement la diarisation en tant qu'outil éditorial, et c'est précisément ce qui manque aux fonctionnalités natives de Premiere.
Comment fonctionne Smart Diarization : De une à dix pistes en 5 minutes
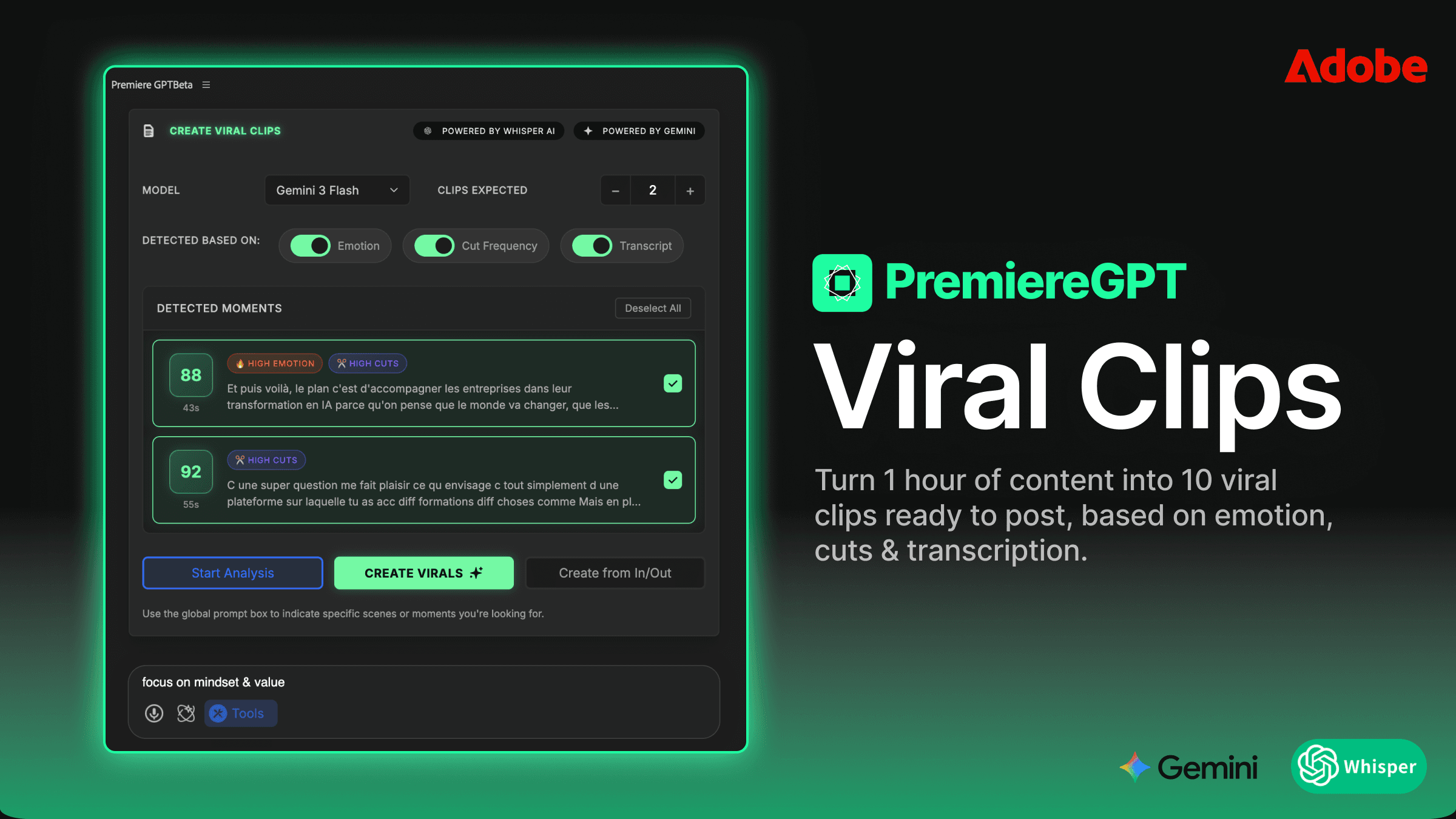
Le seul outil gérant actuellement une véritable séparation des intervenants au niveau de la timeline dans Premiere Pro est l'extension Smart Diarization. Ce n'est pas un flux de travail aller-retour où vous exportez et réimportez. L'extension opère directement sur votre séquence, lit l'audio du clip sélectionné, exécute le modèle de diarisation, puis crée physiquement de nouvelles pistes et les remplit avec les segments correctement attribués — le tout sans quitter la timeline.
Le processus fonctionne ainsi : vous sélectionnez le clip audio mixé, déclenchez l'extension, réglez le nombre d'intervenants attendus et laissez tourner. Une fois terminé, votre clip unique sur A1 a été remplacé par un ensemble de pistes — une par intervenant identifié — avec les segments audio disposés en damier. Les clips sont déjà synchronisés avec votre position d'origine. Votre piste vidéo est intacte. Votre timecode de séquence est préservé.
Ce qui rend cela techniquement significatif, c'est que la séparation se produit au niveau du clip dans la timeline de Premiere. Les clips résultants sont des clips audio Premiere standard. Vous pouvez appliquer des réglages de mixage de piste audio, déposer des plugins VST directement sur chaque piste, et automatiser les niveaux exactement comme vous le feriez avec un montage multipiste manuel.
Prendre en charge jusqu'à 10 intervenants sans quitter la timeline
Pour un podcast standard à deux hôtes, la diarisation est déjà un gain de temps considérable. Mais la valeur réelle apparaît sur les tables rondes ou les conférences où vous pourriez avoir cinq, six ou même dix voix distinctes. Faire le checkerboarding manuel d'un enregistrement à dix intervenants n'est pas un travail de quarante-cinq minutes. C'est un travail d'une demi-journée.
Smart Diarization supporte jusqu'à dix intervenants simultanés en une seule passe. Chaque intervenant reçoit sa propre piste dédiée. Si vous travaillez sur un débat politique ou une réunion d'entreprise, c'est la différence entre un flux de travail qui passe à l'échelle et un autre qui ne le peut pas.
La détection est basée sur la modélisation de la signature vocale, pas sur la séparation des canaux. Cela signifie que cela fonctionne sur de vrais mixages mono et des fichiers stéréo fusionnés — les formats exacts qui causent le plus de problèmes. Vous n'avez pas besoin d'un fichier source multipiste propre pour que cela fonctionne.
Étape par étape : Organiser vos assets pour une structure propre
Avant de lancer la diarisation, votre structure de projet doit être prête. Voici un protocole de configuration propre pour les projets de podcast.
Premièrement, établissez votre structure de chutiers avant l'importation. Créez un dossier maître avec des sous-chutiers : Audio Brut, Clips Diarisés, Musique et SFX, et Séquences. Lorsque le processus crée de nouveaux clips, ils ont besoin d'un foyer désigné.
Deuxièmement, réglez vos paramètres de séquence sur votre livrable audio. Si vous livrez un podcast stéréo en 48kHz/24-bit, vos paramètres de séquence doivent refléter cela avant de commencer à diviser les pistes.
Troisièmement, nommez vos pistes immédiatement après la fin de la diarisation. Dès que vos clips sont distribués de A1 à A4, renommez ces pistes : Hôte 1, Hôte 2, Invité, etc. C'est une étape de trente secondes qui évite bien des confusions lors du mixage.
Quatrièmement, faites un test de synchro avant de commencer tout traitement. Vérifiez qu'un point de référence (un clap, un décompte) est correctement positionné sur les clips diarisés par rapport à votre vidéo.
Cinquièmement, créez un instantané de séquence avant mixage. Dupliquez votre séquence avant d'appliquer des plugins VST. Nommez-la avec le suffixe _PRE-MIX. C'est votre filet de sécurité.
Au-delà de la séparation : Comment la diarisation améliore le mixage
Mettre les intervenants sur des pistes séparées n'est pas le but ultime. C'est le prérequis pour tout ce qui compte dans un mixage professionnel. Une fois que vous avez des pistes discrètes, toute votre chaîne de signal devient intentionnelle.
Considérez le gain staging. Dans une disposition multipiste propre, vous réglez le gain d'entrée de chaque piste indépendamment pour atteindre un niveau cible constant. L'hôte 1 enregistre fort à -6 dBFS — vous baissez le gain. L'invité enregistre bas à -24 dBFS — vous l'augmentez. Maintenant, chaque voix attaque votre compresseur au même niveau, et celui-ci peut faire son vrai travail : contrôler la dynamique, pas compenser des niveaux sources incohérents.
Appliquer des VST spécifiques par intervenant et normaliser les niveaux
Avec les intervenants sur des pistes séparées, l'assignation de plugins VST devient chirurgicale. C'est là que réside la véritable valeur de production.
Une chaîne de traitement typique pourrait inclure : un filtre passe-haut pour nettoyer les grondements graves, un égaliseur dynamique pour les résonances vocales spécifiques, et un compresseur réglé sur la cadence de parole de l'intervenant. L'hôte avec un micro électrostatique dans une pièce traitée a besoin d'une courbe d'égalisation totalement différente de l'invité à distance avec un casque USB dans une cuisine.
L'imbrication de VST est ici particulièrement puissante. Si vous utilisez des plugins tiers comme FabFilter ou iZotope, vous pouvez enregistrer une chaîne complète en tant que preset pour chaque intervenant. À l'épisode suivant, vous chargez le preset et vous mixez en quelques minutes.
Test de performance : Calcul local vs Alternatives Cloud
Toute conversation sérieuse sur les outils de diarisation doit aborder la question de la performance. Vous avez deux options : le traitement local ou le traitement via le cloud.
Les outils basés sur le cloud introduisent des problèmes rédhibitoires : temps d'upload importants, files d'attente imprévisibles et risques pour la confidentialité. Pour des contenus confidentiels (podcasts d'entreprise, interviews sensibles), envoyer l'audio sur un serveur tiers est souvent une violation contractuelle.
Le calcul local résout tout cela. Smart Diarization exécute son modèle sur votre machine. Sur un Mac Apple Silicon moderne ou une station Windows puissante, un épisode de quarante-cinq minutes est traité en moins de cinq minutes. Pas d'upload. Pas de file d'attente. L'audio reste sous votre contrôle.
Le compromis est que les modèles locaux demandent des ressources. Sur du matériel ancien, les temps seront plus longs. Mais même ainsi, le traitement local reste plus rapide que l'alternative manuelle, et les avantages en termes de confidentialité sont non négociables.
L'objectif n'a jamais été d'étiqueter qui a dit quoi. L'objectif a toujours été de mettre chaque voix sur sa propre piste pour que vous puissiez réellement mixer l'émission. Tout le reste n'est qu'une solution à moitié satisfaisante.
La diarisation existe depuis des années. Ce qui manquait, c'était une implémentation là où les monteurs travaillent réellement — dans la timeline. Ce fossé est désormais comblé. Pour les monteurs de podcast, c'est le seul moyen de maintenir une production durable à un niveau de qualité professionnel.
Si vous êtes prêt à construire un mixage de classe mondiale, nous avons préparé le cadre exact pour le faire. Téléchargez le Podcast Mixing Blueprint — une fiche pratique détaillant les courbes d'égalisation, les réglages de compression et les cibles de gain staging à appliquer une fois votre diarisation terminée. Téléchargez le Podcast Mixing Blueprint et essayez Smart Diarization dès aujourd'hui.