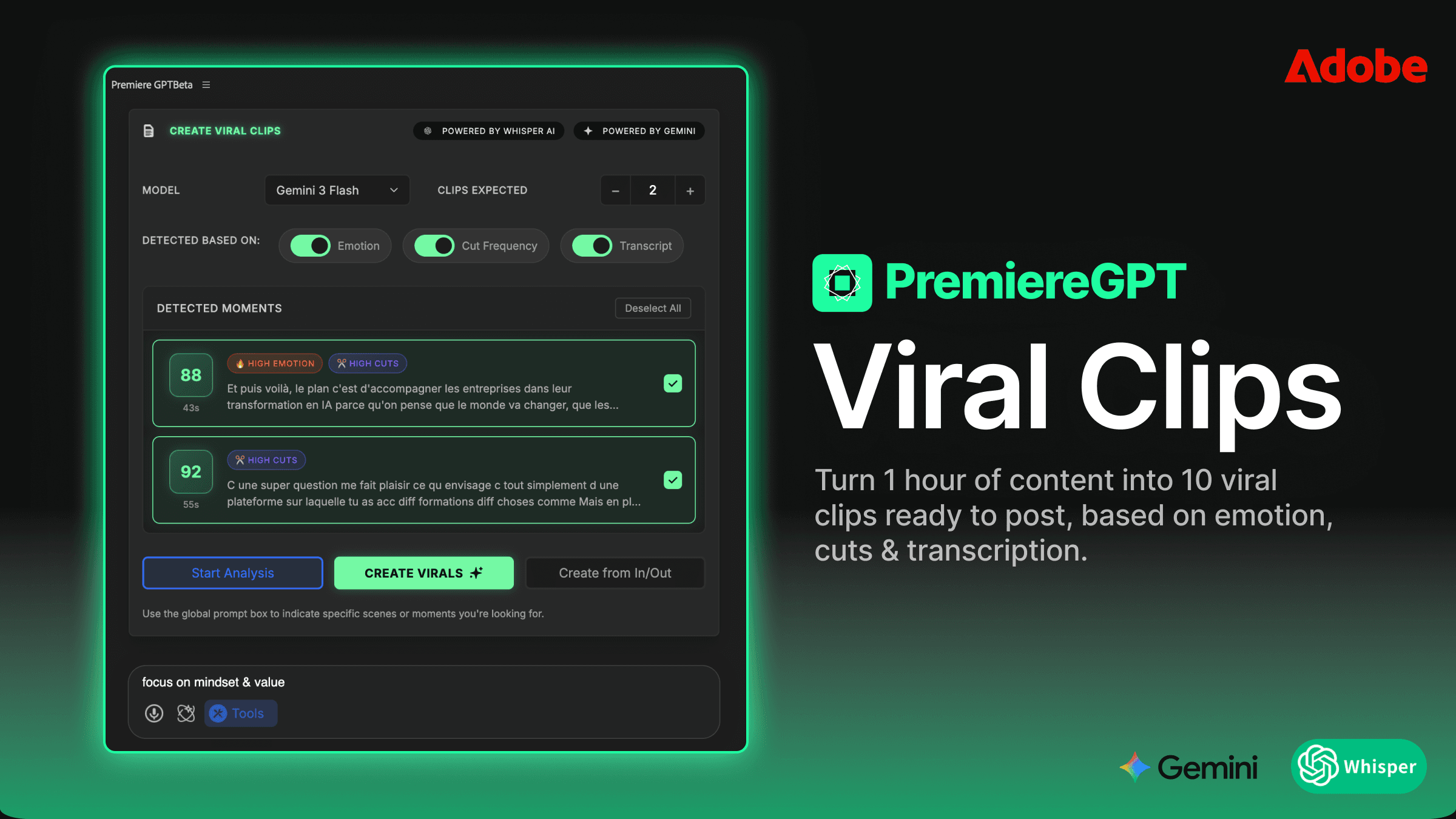
Le piège du montage de rétention : Pourquoi les zooms manuels tuent votre taux horaire
Vous connaissez ce type de montage. Une séquence face caméra. Une seule caméra. Le client veut quelque chose de "dynamique" — énergique, percutant, conçu pour les cycles d'attention courts. Alors vous vous installez et vous commencez à faire la même chose. Vous regardez une phrase, vous placez une image clé sur la propriété Échelle, vous augmentez de 15 %, vous gérez les lissages, vous déplacez la tête de lecture, et vous recommencez. Pour une interview de 10 minutes, on parle de 40 à 80 moments de zoom individuels. C'est des centaines d'images clés. À la main.
C'est le piège du montage de rétention. Le style a été popularisé par une vague de contenus sociaux à haut rendement — le genre où quelque chose change visuellement toutes les trois secondes pour que le pouce du spectateur reste immobile. Ça marche. Le problème, c'est le coût de la main-d'œuvre. Si vous facturez un forfait par vidéo et passez quatre heures uniquement sur les zooms, vous perdez activement de l'argent à chaque fois que vous ouvrez cette séquence.
Et le pire ? La plupart de ces zooms sont arbitraires. Vous ne réagissez pas à la prestation de l'orateur. Vous remplissez simplement l'espace avec du mouvement parce que le montage semble trop statique. Vous appliquez une technique sans véritable déclencheur, ce qui signifie que le résultat semble souvent mécanique — des zooms qui tombent sur la mauvaise syllabe, des punch-ins qui arrivent pendant une respiration au lieu d'une chute.
Il existe une meilleure façon de procéder, et cela commence par séparer la question de quand zoomer de la question de comment l'exécuter. La première partie — le quand — est en réalité un problème de données. Et les problèmes de données peuvent être automatisés.
Détection d'émotions vs Mathématiques statiques : Comment l'algorithme identifie les moments 'clés' pour un zoom
La plupart des plugins de zoom automatique de base fonctionnent sur des mathématiques statiques. Ils regardent l'amplitude audio, trouvent les pics les plus forts et placent un zoom sur ces images. C'est un instrument rudimentaire. Fort ne veut pas dire important. Un orateur qui se racle la gorge est fort. Un coup sur la table est fort. Le moment réel de l'accentuation émotionnelle — la pause avant le mot clé, la légère montée de ton sur une phrase critique — ce ne sont souvent pas les moments les plus forts de la forme d'onde. Ce sont les moments les plus significatifs, et l'amplitude seule ne peut pas les trouver.
La détection d'émotions fonctionne à un niveau différent. Au lieu de simplement lire le signal audio, elle analyse le contenu de la parole, la prosodie (le rythme, l'accentuation et l'intonation de la parole) et le poids sémantique de ce qui est dit. L'algorithme pose une question fondamentalement différente. Il ne demande pas "où est le pic audio ?" Il demande "où l'orateur est-il au sommet de sa prestation émotionnelle ?"
En pratique, cela signifie que le système peut identifier des moments comme un orateur qui insiste sur une conclusion, une question rhétorique qui fait mouche, un moment de vulnérabilité ou d'insistance — le genre de battements qu'un monteur expérimenté ressentirait instinctivement en regardant les images. L'IA ne regarde pas les images, mais elle analyse les mêmes signaux auxquels un monteur qualifié répondrait : changement de ton, changement de rythme, climax sémantique.
Le résultat est un placement de zoom qui suit réellement l'arc de la prestation de l'orateur plutôt que seulement les pics les plus forts du fichier audio. Lorsque vous examinez les effets générés par l'IA dans votre timeline, vous constaterez que les zooms tombent sur des moments que vous auriez choisis vous-même — ce qui signifie moins de temps à corriger les mauvais placements et plus de temps à faire les quelques ajustements qui nécessitent réellement un jugement éditorial.
Ce n'est pas de la magie. C'est une tâche d'automatisation bien définie. L'algorithme ne prend pas de décisions créatives — il fait ressortir les moments qui sont statistiquement les plus susceptibles de bénéficier d'une emphase visuelle. Vous décidez toujours si cette emphase est appropriée pour la pièce spécifique. Mais maintenant, vous prenez cette décision sur 10 % des zooms au lieu de les placer à 100 % à partir de zéro.
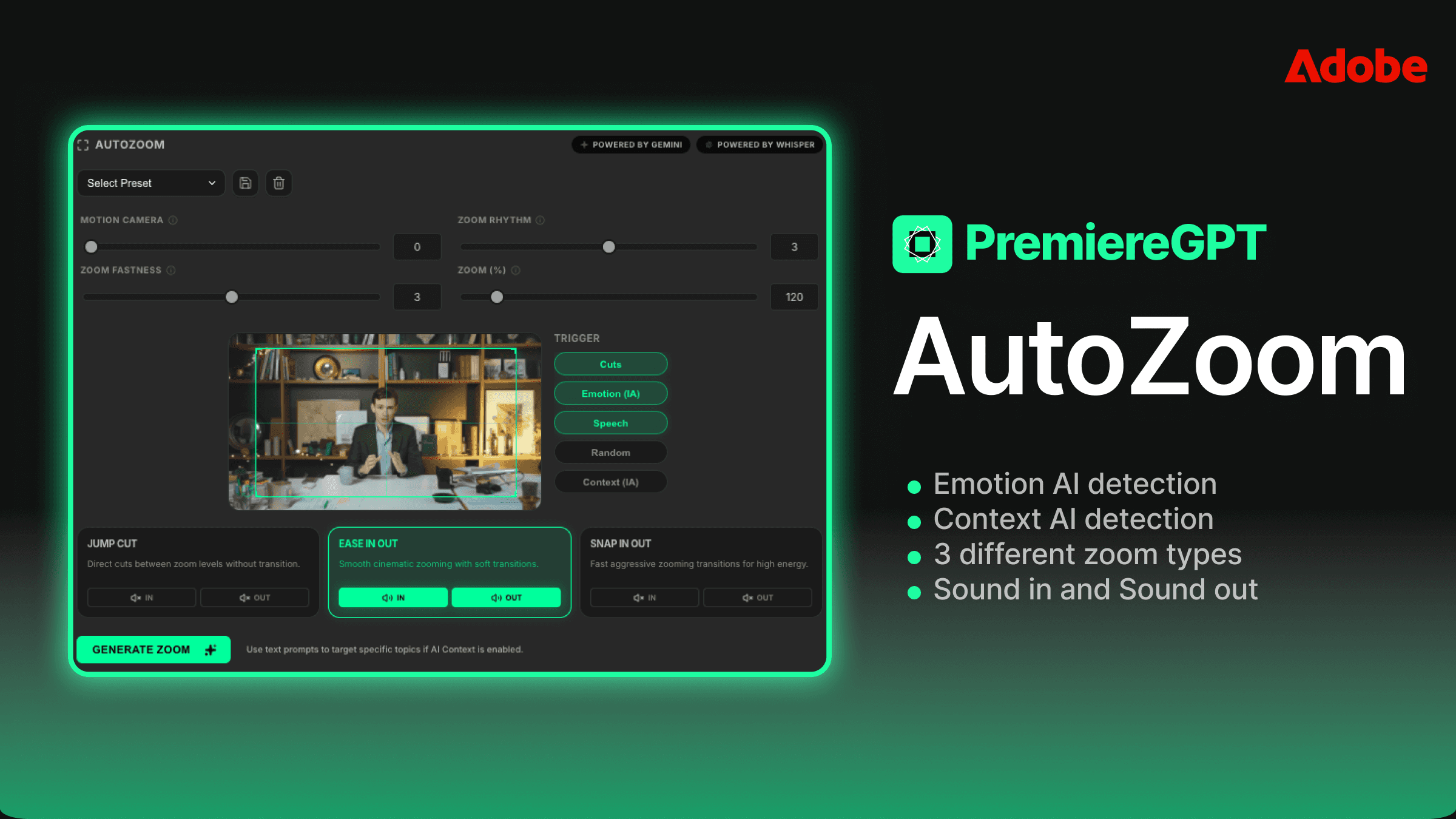
Au-delà du recadrage : Personnaliser la vitesse, le sound design et les prompts contextuels de l'IA pour le 'vibe' parfait
Un zoom n'est pas juste un zoom. La différence entre un zoom avant de 4 images avec un effet sonore "whoosh" et un zoom fluide de 12 images sans traitement audio est la différence entre une vidéo dynamique et un documentaire. La vitesse et le design sonore sont les variables qui définissent le registre émotionnel d'un montage de rétention, et tout outil d'automatisation sérieux doit vous donner le contrôle sur les deux.
Lors de la configuration de vos passes d'auto-zoom, vous travaillez avec deux profils de vitesse principaux. Les zooms rapides — généralement de 3 à 6 images — sont vos coupes à haute énergie. Ils fonctionnent pour le contenu de motivation, les moments de réaction, les chutes. Ils semblent agressifs et ils doivent l'être. Les zooms fluides — 10 à 20 images avec une interpolation lissée — sont destinés au contenu narratif, aux moments émotionnels, aux segments explicatifs où vous voulez attirer le spectateur plutôt que de le bousculer. Utiliser le mauvais profil de vitesse sur le bon moment reste un mauvais montage.
La superposition du sound design sur les zooms est souvent traitée comme une réflexion après coup, mais c'est en fait l'un des éléments les plus puissants du montage de rétention. Un léger bruit sourd à basse fréquence sous un zoom lent ajoute du poids. Un sifflement aigu sous un zoom rapide ajoute du punch. Le traitement audio indique au cerveau du spectateur comment se sentir par rapport au mouvement visuel avant même qu'il ne l'ait consciemment traité.
La fonctionnalité de prompt contextuel de l'IA est l'endroit où le flux de travail devient véritablement sophistiqué. Au lieu d'appliquer un algorithme de zoom universel, vous pouvez fournir au système une brève description de l'intention émotionnelle du contenu. Un prompt comme "contenu commercial motivant, haute énergie, orateur confiant" calibrera le seuil de détection différemment de "histoire personnelle, vulnérabilité émotionnelle, rythme lent". L'algorithme utilise le contexte pour pondérer les signaux émotionnels à prioriser lors de la sélection des points de déclenchement du zoom.
Pensez-y comme si vous donniez des instructions à l'IA de la même manière que vous le feriez avec un monteur junior. Vous ne lui donnez pas un script image par image — vous lui donnez assez de contexte pour prendre de meilleures décisions dans son champ d'action. Plus votre prompt est spécifique, plus le résultat reflète le ton réel de la pièce plutôt qu'un modèle générique de montage de rétention.
Flux de travail non destructif : Pourquoi garder les zooms sur des calques d'effets est préférable aux séquences imbriquées
Voici la partie la plus importante d'un point de vue professionnel, et c'est ce qui sépare un outil digne d'être utilisé d'un outil qui crée plus de problèmes qu'il n'en résout.
Lorsque PremiereCopilot applique des auto-zooms à votre timeline, il n'intègre pas le mouvement dans vos clips. Il n'imbrique pas vos séquences. Il ne touche pas à vos médias originaux. Il applique les effets de zoom sous forme de Calques d'Effets — des calques de type réglage dédiés placés au-dessus de vos séquences dans la timeline, contenant toutes les images clés d'Échelle et de Position générées par la passe d'IA.
Pourquoi est-ce important ? Parce que les séquences imbriquées sont un piège. Une fois que vous imbriquez un clip pour lui appliquer un mouvement, vous avez ajouté une couche d'abstraction entre vous et votre montage. Besoin de raccourcir le clip ? Vous gérez maintenant les points d'entrée et de sortie sur deux niveaux de la timeline. Besoin d'échanger la séquence sous-jacente ? Vous devez entrer dans l'imbrication. Besoin de supprimer complètement le zoom ? Vous supprimez soit l'imbrication, soit vous allez à l'intérieur. Chaque opération qui devrait être simple devient un processus en deux étapes.
Les calques d'effets gardent tout à la même profondeur de timeline. Le zoom est sur un calque au-dessus du clip. Vous pouvez le voir, le sélectionner, le supprimer, le déplacer ou ajuster ses images clés directement dans le panneau Options d'effet — exactement de la même manière que vous travailleriez avec n'importe quel autre effet dans Premiere Pro. L'IA a fait le gros du travail de placement et de timing, mais vous avez un contrôle éditorial à 100 % sur chaque zoom généré. Rien n'est verrouillé. Rien n'est caché dans une imbrication.
Cette architecture signifie également que les zooms sont complètement portables. Si vous devez déplacer un clip dans la timeline, le calque d'effets se déplace avec lui. Si vous souhaitez copier un traitement de zoom d'un segment à un autre, vous copiez un calque, pas une séquence imbriquée en double avec toute la lourdeur que cela implique.
Pour les monteurs produisant du contenu social à haut volume — plusieurs montages par semaine, plusieurs formats d'image, cycles de révision rapides — cette approche non destructive n'est pas un luxe. C'est le seul flux de travail qui passe à l'échelle sans créer de dette technique dans vos fichiers de projet.
Comment configurer vos presets AutoZoom pour des montages sociaux 10x plus rapides
Le gain d'efficacité réel du zoom assisté par l'IA ne provient pas d'une seule exécution sur une seule vidéo. Il provient de la création d'une bibliothèque de presets qui reflète votre style de montage spécifique et les types de contenu spécifiques de vos clients. Voici comment structurer ce système.
Étape 1 : Définissez vos catégories de contenu. La plupart des monteurs travaillant dans l'espace des réseaux sociaux découpent quelques types de contenu récurrents — contenu de motivation/business, explications éducatives, récits personnels, clips d'interview/podcast. Chacun d'eux a une densité de zoom optimale différente (combien de zooms par minute), un profil de vitesse différent et un traitement de sound design différent. Documentez-les avant de créer vos presets.
Étape 2 : Créez vos presets de base par catégorie. Pour chaque type de contenu, configurez un preset avec votre réglage de densité de zoom, votre profil de vitesse (rapide vs fluide), votre couche de design sonore préférée et votre prompt contextuel IA par défaut. Nommez ces presets clairement — "Business Motivation - Haute Énergie", "Clip Podcast - Conversationnel", "Histoire - Émotionnel". Lorsqu'un nouveau projet arrive, vous sélectionnez un preset, vous ne reconstruisez pas vos réglages à partir de zéro.
Étape 3 : Lancez la passe d'IA et faites une seule passe de révision. Une fois l'auto-zoom exécuté et les calques d'effets placés dans votre timeline, faites une passe de révision ciblée. Vous ne construisez rien — vous supprimez seulement les zooms qui ne fonctionnent pas et ajustez occasionnellement le timing de ceux qui sont proches mais pas exacts. Sur un preset bien configuré appliqué à un contenu approprié, vous devriez supprimer ou ajuster moins de 20 % des zooms générés. Si vous en ajustez plus, votre preset a besoin d'être affiné, pas de plus de travail manuel.
Étape 4 : Itérez vos prompts en fonction des résultats. Notez quels prompts contextuels d'IA ont produit le meilleur placement de zoom pour chaque type de contenu. Au fil du temps, vous développerez un vocabulaire de prompts adapté à vos clients et styles de contenu spécifiques. C'est le retour sur investissement du système — chaque vidéo que vous montez rend vos presets légèrement plus précis, ce qui signifie légèrement moins de travail de révision sur la suivante.
Étape 5 : Créez vos variantes de montages sociaux à partir de la même pile de calques d'effets. Si vous montez un format 16:9 long et un format 9:16 court à partir des mêmes images, vos calques d'effets peuvent être adaptés plutôt que reconstruits. Les positions et le timing du zoom sont déjà établis — vous ajustez les valeurs d'Échelle et les points d'ancrage pour le recadrage, pas l'exécution complète de la passe d'IA.
Le gain de temps cumulé sur un mois de travail de contenu social est significatif. Nous parlons de passer de quatre heures de travail de zoom manuel par vidéo à moins de 45 minutes de configuration, de révision et d'affinage. Ce n'est pas une estimation tirée d'un argumentaire marketing — c'est le calcul mathématique du remplacement de centaines d'images clés manuelles par une seule passe d'IA et une révision éditoriale ciblée.
L'objectif n'a jamais été de retirer le monteur du processus. L'objectif est de supprimer les parties mécaniques du processus afin que le temps du monteur soit consacré à des décisions qui nécessitent réellement un jugement.
Si vous créez encore manuellement des images clés sur les propriétés d'Échelle à chaque coupe de tête parlante, vous ne faites pas de montage — vous faites de la saisie de données. La technique a sa place, mais l'exécution doit être automatisée partout où l'automatisation est suffisamment précise pour être fiable. Avec la détection d'émotions pilotant le placement et les calques d'effets préservant votre contrôle, elle l'est.
Prêt à arrêter de créer des presets de zoom à partir de zéro à chaque fois ? Téléchargez le guide pratique du montage de rétention — un PDF couvrant exactement quand utiliser les profils de zoom Rapide vs Fluide, une liste organisée de prompts contextuels IA par type de contenu, et un tableau de référence de la densité de zoom pour les formats sociaux les plus courants. Tout ce dont vous avez besoin pour configurer votre première passe de zoom assistée par l'IA et obtenir des résultats que vous garderez réellement au montage.